gpt 5.6 sol pro 빨리 써보고 싶군요
발전이 크네요
GeneBench-Pro는 AI가 실제 생명과학 연구에서 필요한 판단력을 얼마나 갖췄는지 평가하는 고난도 벤치마크입니다.
단순히 생물학 지식을 많이 알고 있느냐, 정해진 분석 절차를 따라갈 수 있느냐를 보는 것이 아닙니다.
실제 연구에서는 데이터 속 패턴이 생물학적 의미가 있는지, 단순한 노이즈인지 판단해야 하고, 이 데이터로 애초에 질문에 답할 수 있는지도 따져봐야 합니다. 또 분석 과정에서 가정이 틀렸다고 판단되면 방향을 바꾸고, 결과가 의사결정에 쓸 수 있을 만큼 충분한지도 판단해야 합니다.
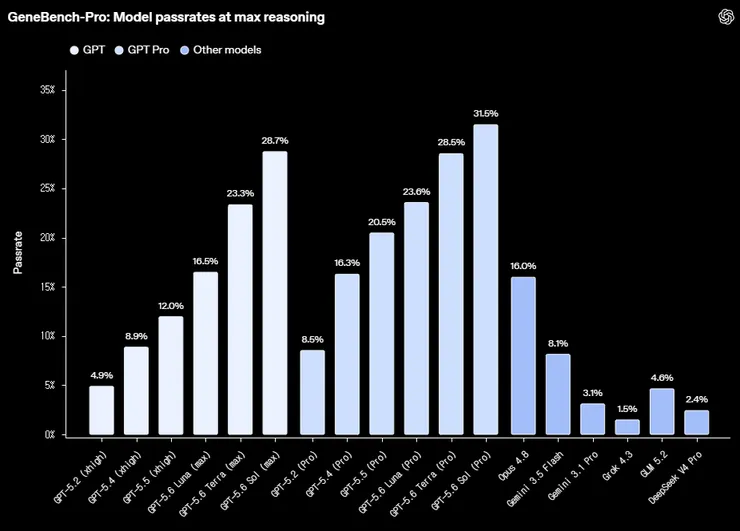
GeneBench-Pro는 바로 이런 능력, 즉 연구자의 ‘분석 감각’과 ‘판단력’을 평가하기 위해 만들어진 벤치마크입니다. 유전체학, 정량생물학, 중개의학 등 실제 계산생물학 연구에 가까운 복잡하고 애매한 문제 129개로 구성되어 있습니다.
흥미로운 점은 문제 난도가 상당히 높다는 것입니다. 평가자들은 GeneBench-Pro의 일반적인 한 문제를 인간 전문가가 풀려면 약 20~40시간이 걸릴 것으로 봤습니다. 시간당 200달러로 계산하면 문제 하나당 수천 달러 수준의 인건비가 들어가는 셈입니다.
그런데 GPT-5.6 Sol Pro는 이 벤치마크에서 최대 31.5%를 기록했습니다. 아직 AI 에이전트가 인간 전문가를 대체할 만큼 안정적인 수준은 아니지만, 추론 비용이 문제당 몇 달러 수준이라는 점을 생각하면 의미가 큽니다.
즉, 지금 당장은 완전 자동화는 어렵더라도, 일부 분석 과정을 보조하거나 자동화하는 것만으로도 과학 연구와 비용 측면에서 꽤 큰 가치를 만들 수 있다는 뜻입니다.
GeneBench-Pro 벤치마크 (높은 순 정렬)
GPT-5.6 Sol (Pro) : 31.5%
GPT-5.6 Sol (max) : 28.7%
GPT-5.6 Terra (Pro) : 28.5%
GPT-5.6 Luna (Pro) : 23.6%
GPT-5.6 Terra (max) : 23.3%
GPT-5.5 (Pro) : 20.5%
GPT-5.6 Luna (max) : 16.5%
GPT-5.4 (Pro) : 16.3%
Opus 4.8 : 16.0%
GPT-5.5 (xhigh) : 12.0%
GPT-5.4 (xhigh) : 8.9%
GPT-5.2 (Pro) : 8.5%
Gemini 3.5 Flash : 8.1%
GPT-5.2 (xhigh) : 4.9%
GLM 5.2 : 4.6%
Gemini 3.1 Pro : 3.1%
DeepSeek V4 Pro : 2.4%
Grok 4.3 : 1.5%
https://www.clien.net/service/board/park/18925916CLIEN