복잡한 과제 해결을 위해 더욱 스마트해진 ‘제미나이 3.1 프로’
제미나이 3.1 프로는 단편적인 문답을 넘어, 고도의 추론이 요구되는 고난도 작업을 위해 설계되었습니다.
지난주, 구글은 과학, 연구 및 엔지니어링 분야의 현대적 과제들을 해결하기 위해 제미나이 3 딥 씽크(Gemini 3 Deep Think)의 대규모 업데이트를 발표했습니다. 그리고 오늘, 이러한 혁신의 기반이 된 핵심 인텔리전스의 업그레이드 버전인 제미나이 3.1 프로를 출시합니다. 구글은 향상된 AI 모델을 일상적인 애플리케이션에서 직접 경험할 수 있도록 일반 이용자 및 개발자용 제품 전반에 3.1 프로를 확대 적용합니다.
제미나이 3.1 프로는 오늘부터 다음과 같이 순차 배포됩니다:
- 개발자: 업그레이드된 구글 AI 스튜디오(Google AI Studio)의 제미나이 API, 제미나이 CLI, 에이전트 개발 플랫폼인 구글의 에이전틱 AI 개발 플랫폼인 구글 안티그래비티(Google Antigravity), 안드로이드 스튜디오(Android Studio)를 통해 프리뷰 버전 제공
- 기업: 버텍스 AI(Vertex AI) 및 제미나이 엔터프라이즈(Gemini Enterprise)를 통해 제공
- 일반 이용자: 제미나이 앱 및 노트북LM(NotebookLM)을 통해 제공
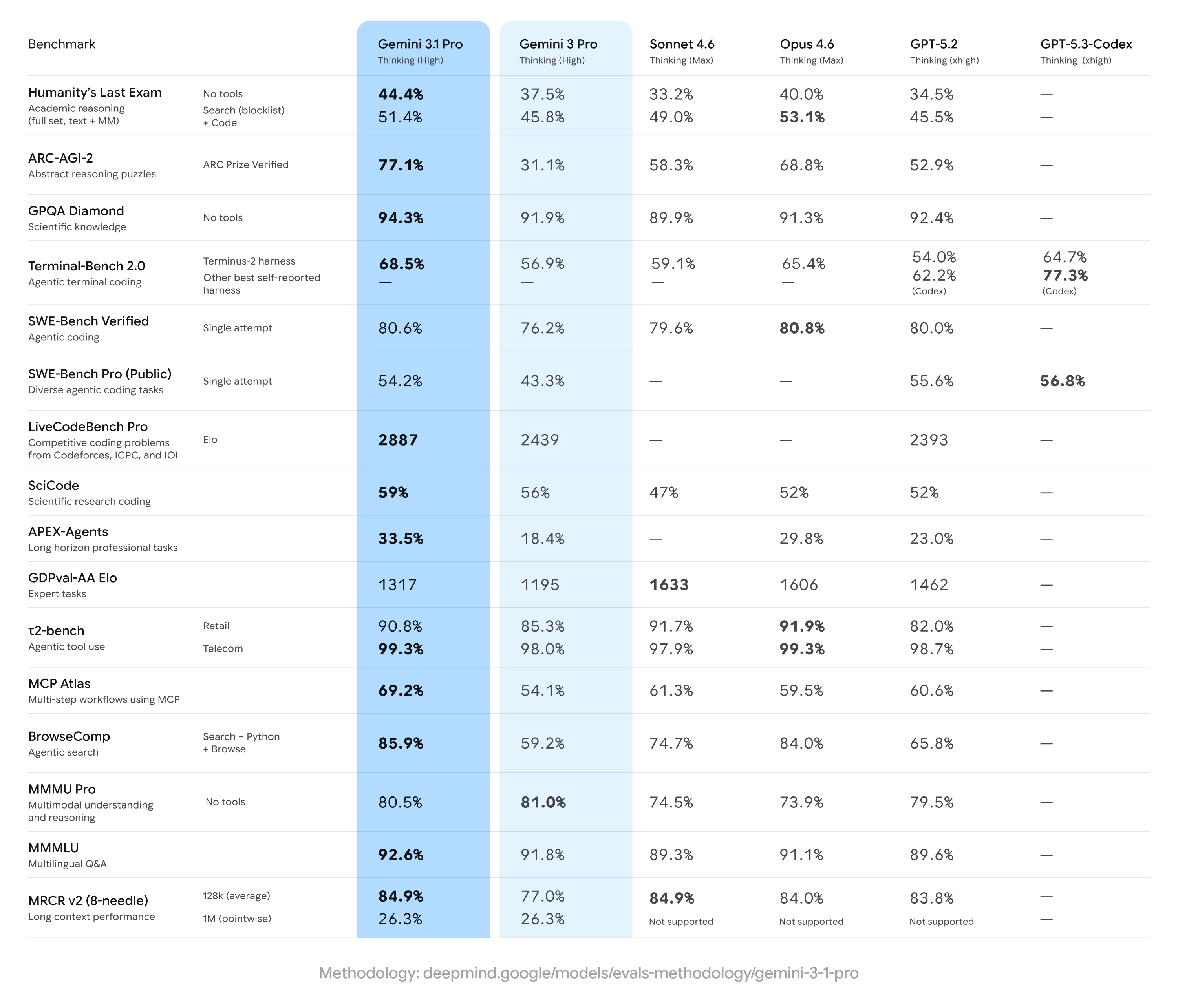
제미나이 3(Gemini 3) 시리즈를 기반으로 구축된 3.1 프로는 핵심 추론 능력을 비약적으로 발전시켰습니다. 3.1 프로는 복잡한 문제를 해결하는 데 더욱 스마트하고 강력한 기준점(baseline)을 제시합니다. 이러한 성능 향상은 엄격한 벤치마크 결과로도 입증됩니다. 완전히 새로운 논리 패턴 해결 능력을 평가하는 벤치마크인 ‘ARC-AGI-2’에서 3.1 프로는 77.1%를 기록하며, 이전 버전인 3 프로 대비 두 배 이상 향상된 추론 성능을 달성했습니다.
실무 현장에 최적화된 인텔리전스
제미나이 3.1 프로는 단편적인 결과물 도출을 넘어, 고도화된 추론 능력을 바탕으로 비즈니스 현장의 까다로운 과제들을 해결하도록 설계되었습니다. 특히 모델 스스로 최적의 솔루션 구축 방식을 판단하고 실행해야 하는 워크플로우에서 탁월한 성능을 발휘합니다. 또한, 복잡한 개념의 시각적 구현, 데이터를 단일 뷰로 통합하는 방법, 창의적인 프로젝트를 현실로 구현하는 등 다양한 실무 영역에서 실무적인 가치를 제공합니다.
코드 기반 애니메이션: 텍스트 프롬프트만으로 웹사이트에 즉시 적용 가능한 애니메이션 SVG를 직접 생성합니다. 픽셀 방식이 아닌 순수 코드로 구현되기 때문에 어떤 화면 크기에서도 선명도를 유지하며, 기존 영상 포맷 대비 파일 크기도 획기적으로 줄여줍니다
복잡한 시스템 합성: 3.1 프로는 고급 추론 능력을 활용해 복잡한 API 데이터와 이용자 친화적인 디자인을 매끄럽게 연결합니다. 이 예시에서 모델은 실시간 항공우주 대시보드를 구축하여 공공 텔레메트리 스트림(public telemetry stream)을 성공적으로 구성하고 국제 우주 정거장(ISS)의 궤도를 시각화했습니다.
인터랙티브 디자인: 복잡한 3D 찌르레기 떼의 군무(murmuration)를 코딩으로 완벽하게 구현합니다. 시각적 이미지 생성을 넘어, 이용자가 핸드 트래킹으로 시계를 조작하고 새들의 움직임에 맞춰 반응하는 생성형 음악까지 결합된 몰입형 경험을 구축합니다. 이는 연구진과 디자이너가 감각적인 인터페이스를 프로토타이핑할 수 있는 강력한 방법을 제공합니다.
크리에이티브 코딩: 문학적 테마를 실제 구동되는 기능적 코드로 변환합니다. 에밀리 브론테의 소설 '폭풍의 언덕'을 위한 현대적인 개인 포트폴리오를 구축하라는 요청에 대해, 모델은 단편적인 텍스트 요약에 그치지 않고 소설 특유의 분위기 있는 톤을 추론하여 세련되고 현대적인 인터페이스를 설계하고, 주인공의 본질을 담아낸 웹사이트를 완성합니다.
향후 계획
구글은 이미 많은 진전을 이루었지만, 한발 더 나아가 더욱 야심 찬 에이전트 워크플로우(agentic workflows)내에서 모델 성능을 한층 더 개선하는 방향을 모색하고 있습니다. 앞으로도 구글은 코딩 및 확장된 에이전트 워크플로우 환경에서 3.1 프로의 성능을 지속적으로 향상시킬 것입니다.
오늘부터 제미나이 앱의 제미나이 3.1 프로가 구글 AI 프로(Google AI Pro) 및 울트라(Ultra) 플랜 구독자들을 대상으로 상향된 사용 한도가 적용되어 제공됩니다. 또한 3.1 프로는 이제 노트북LM에서 프로 및 울트라 이용자 대상 독점 제공됩니다. 아울러 개발자와 기업은 지금 바로 구글 AI 스튜디오, 안티그래비티, 버텍스 AI, 제미나이 엔터프라이즈, 제미나이 CLI 및 안드로이드 스튜디오의 제미나이 API에서 3.1 프로 프리뷰 버전을 이용할 수 있습니다.
여러분이 제미나이 3.1 프로를 활용해 선보일 창의적인 결과물과 새로운 발견을 기대합니다.
https://twitter.com/GoogleDeepMind/status/2024516467618656357
https://twitter.com/Google/status/2024519479577747562
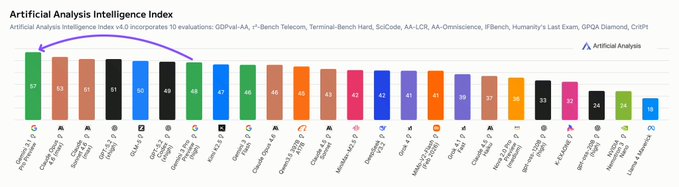
Google이 다시 한번 AI 분야의 선두주자로 자리매김하였습니다. Gemini 3.1 Pro Preview는 Artificial Analysis 지능 지수(Intelligence Index)에서 1위를 차지하였으며, 운영 비용을 절반 이하로 낮추면서도 Claude Opus 4.6보다 4점 앞선 성적을 기록하였습니다. @GoogleDeepMind는 당사에 Gemini 3.1 Pro Preview에 대한 사전 출시 액세스 권한을 제공하였습니다. 해당 모델은 Artificial Analysis 지능 지수를 구성하는 10개 평가 항목 중 6개 항목에서 1위를 기록하였으며, Gemini 3 Pro Preview 대비 성능이 대폭 향상되었습니다. 특히 추론 및 지식, 코딩, 환각 감소 분야에서 가장 큰 진전을 보였습니다.
Gemini 3.1 Pro Preview는 또한 상대적으로 높은 토큰 효율성을 유지하고 있습니다. Artificial Analysis 지능 지수 실행에 약 5,700만 개의 토큰을 사용하였으며(Gemini 3 Pro Preview 대비 100만 개 증가), 이는 Opus 4.6(max) 및 GPT-5.2(xhigh)와 같은 최대 추론 설정에서의 다른 프론티어 모델보다 낮은 수준입니다. 토큰당 가격이 더 저렴하다는 점과 결합되어, Gemini 3.1 Pro Preview는 프론티어 동급 모델 중 비용 효율성이 뛰어납니다. 전체 지능 지수를 실행하는 데 드는 비용은 Opus 4.6(max)의 절반 미만이지만, 선도적인 오픈 웨이트 모델인 GLM-5보다는 여전히 약 2배 높습니다.
주요 요약:
➤ 낮은 비용으로 구현하는 최첨단 지능: Gemini 3.1 Pro Preview는 @OpenAI 및 @AnthropicAI의 프론티어 동급 모델 대비 운영 비용이 절반 미만이면서도, Artificial Analysis 지능 지수를 구성하는 10개 평가 항목 중 6개에서 선두를 달리고 있습니다. 본 모델은 Terminal-Bench Hard(에이전틱 코딩), AA-Omniscience(지식 및 환각), Humanity’s Last Exam(추론 및 지식), GPQA-Diamond(과학적 추론), SciCode(코딩) 및 CritPt(연구 수준 물리학)에서 최고 점수를 획득하였습니다. 특히 CritPt 점수는 주목할 만한데, 미발표된 연구 수준의 물리학 추론 문제에서 18%를 기록하며 차순위 모델보다 5%p 이상 높은 점수를 보였습니다.
➤ 개선된 실세계 에이전틱 성능, 다만 선두는 아님: Gemini 3.1 Pro Preview는 실세계 작업에 중점을 둔 당사의 에이전틱 평가인 GDPval-AA에서 개선된 모습을 보였으나, 아직 이 분야의 선두 모델은 아닙니다. 해당 모델의 ELO 점수는 Gemini 3 Pro Preview 대비 100점 이상 상승한 1316점을 기록하였으나, Claude Sonnet 4.6, Opus 4.6, GPT-5.2(xhigh) 및 GLM-5보다는 뒤처져 있습니다.
➤ 선도적인 코딩 능력: Gemini 3.1 Pro Preview는 Artificial Analysis 코딩 지수에서 1위를 차지하였으며, Terminal-Bench Hard(54%)와 SciCode(59%) 모두에서 최고 점수를 달성하였습니다.
➤ 환각 현상 감소: Gemini 3.1 Pro Preview는 정답을 모를 때 부정확하게 추측하는 경향이 크게 개선되었으며, AA-Omniscience 환각률을 Gemini 3 Pro Preview 대비 38%p 감소시켰습니다.
➤ 토큰 및 비용 효율성 유지: Gemini 3.1 Pro Preview는 비용이나 토큰 사용량의 실질적인 증가 없이 성능을 향상시켰습니다. Artificial Analysis 지능 지수 실행 시 Gemini 3 Pro Preview보다 약 2% 많은 토큰만을 사용하며, 동일한 가격 책정($2/$12 per 1M input/output tokens for ≤200k context)을 유지합니다. Artificial Analysis 지능 지수를 실행하는 데 드는 비용은 $892로, Opus 4.6(max) 및 GPT-5.2(xhigh)와 같은 프론티어 모델의 절반 미만입니다. 다만 선도적인 오픈 웨이트 모델인 GLM 5($547)보다는 여전히 약 2배 높습니다.
➤ Google이 멀티모달리티 부문 상위 3위 석권: Gemini 3.1 Pro Preview는 당사의 멀티모달 이해 및 추론 벤치마크인 MMMU-Pro에서 Gemini 3 Pro Preview와 Gemini 3 Flash를 제치고 1위를 차지하며, 멀티모달 추론 분야에서 Google의 리더십을 공고히 하였습니다.
➤ 기타 모델 세부 사항: Gemini 3.1 Pro Preview는 이전 모델과 동일한 100만 토큰 컨텍스트 창을 유지하며, 도구 호출(tool calling), 구조화된 출력(structured outputs) 및 JSON 모드 지원을 포함합니다.
https://twitter.com/ArtificialAnlys/status/2024518562283737414
Gemini 3.1 Pro Preview - Intelligence, Performance & Price Analysis
Gemini 3.1 Pro Preview는 또한 상대적으로 높은 토큰 효율성을 유지하고 있습니다. Artificial Analysis 지능 지수 실행에 약 5,700만 개의 토큰을 사용하였으며(Gemini 3 Pro Preview 대비 100만 개 증가), 이는 Opus 4.6(max) 및 GPT-5.2(xhigh)와 같은 최대 추론 설정에서의 다른 프론티어 모델보다 낮은 수준입니다. 토큰당 가격이 더 저렴하다는 점과 결합되어, Gemini 3.1 Pro Preview는 프론티어 동급 모델 중 비용 효율성이 뛰어납니다. 전체 지능 지수를 실행하는 데 드는 비용은 Opus 4.6(max)의 절반 미만이지만, 선도적인 오픈 웨이트 모델인 GLM-5보다는 여전히 약 2배 높습니다.
주요 요약:
➤ 낮은 비용으로 구현하는 최첨단 지능: Gemini 3.1 Pro Preview는 @OpenAI 및 @AnthropicAI의 프론티어 동급 모델 대비 운영 비용이 절반 미만이면서도, Artificial Analysis 지능 지수를 구성하는 10개 평가 항목 중 6개에서 선두를 달리고 있습니다. 본 모델은 Terminal-Bench Hard(에이전틱 코딩), AA-Omniscience(지식 및 환각), Humanity’s Last Exam(추론 및 지식), GPQA-Diamond(과학적 추론), SciCode(코딩) 및 CritPt(연구 수준 물리학)에서 최고 점수를 획득하였습니다. 특히 CritPt 점수는 주목할 만한데, 미발표된 연구 수준의 물리학 추론 문제에서 18%를 기록하며 차순위 모델보다 5%p 이상 높은 점수를 보였습니다.
➤ 개선된 실세계 에이전틱 성능, 다만 선두는 아님: Gemini 3.1 Pro Preview는 실세계 작업에 중점을 둔 당사의 에이전틱 평가인 GDPval-AA에서 개선된 모습을 보였으나, 아직 이 분야의 선두 모델은 아닙니다. 해당 모델의 ELO 점수는 Gemini 3 Pro Preview 대비 100점 이상 상승한 1316점을 기록하였으나, Claude Sonnet 4.6, Opus 4.6, GPT-5.2(xhigh) 및 GLM-5보다는 뒤처져 있습니다.
➤ 선도적인 코딩 능력: Gemini 3.1 Pro Preview는 Artificial Analysis 코딩 지수에서 1위를 차지하였으며, Terminal-Bench Hard(54%)와 SciCode(59%) 모두에서 최고 점수를 달성하였습니다.
➤ 환각 현상 감소: Gemini 3.1 Pro Preview는 정답을 모를 때 부정확하게 추측하는 경향이 크게 개선되었으며, AA-Omniscience 환각률을 Gemini 3 Pro Preview 대비 38%p 감소시켰습니다.
➤ 토큰 및 비용 효율성 유지: Gemini 3.1 Pro Preview는 비용이나 토큰 사용량의 실질적인 증가 없이 성능을 향상시켰습니다. Artificial Analysis 지능 지수 실행 시 Gemini 3 Pro Preview보다 약 2% 많은 토큰만을 사용하며, 동일한 가격 책정($2/$12 per 1M input/output tokens for ≤200k context)을 유지합니다. Artificial Analysis 지능 지수를 실행하는 데 드는 비용은 $892로, Opus 4.6(max) 및 GPT-5.2(xhigh)와 같은 프론티어 모델의 절반 미만입니다. 다만 선도적인 오픈 웨이트 모델인 GLM 5($547)보다는 여전히 약 2배 높습니다.
➤ Google이 멀티모달리티 부문 상위 3위 석권: Gemini 3.1 Pro Preview는 당사의 멀티모달 이해 및 추론 벤치마크인 MMMU-Pro에서 Gemini 3 Pro Preview와 Gemini 3 Flash를 제치고 1위를 차지하며, 멀티모달 추론 분야에서 Google의 리더십을 공고히 하였습니다.
➤ 기타 모델 세부 사항: Gemini 3.1 Pro Preview는 이전 모델과 동일한 100만 토큰 컨텍스트 창을 유지하며, 도구 호출(tool calling), 구조화된 출력(structured outputs) 및 JSON 모드 지원을 포함합니다.
Gemini 의 가장 고질적인 문제인데 이게 사용량과 관계가 있는거 같다라고요.
Claude 나 ChatGPT 는 사용량이 차면 얼마 이후 이용하라고 메시지를 내는데 Gemini 는 그러한 것 없이 그냥 내가 상위 모델을 선택해 작업하더라도 인의적으로 하위모델로 스우칭해서 답변을 주는 구조 같아요. 아니면 다른 모델들 보다 Context Token 이 길어지면 엉망이 되거나 말이죠. 그래서 솔직히 Gemini 로 작업하기 두려운게 앞에 작업 했던 것 까지 다 엉망으로 만들어 버려서 시간만 낭비하는 경우가 많죠.
cc등의 angentic 도구들은 적당히 summary 를 만들어서 보관하는데 gemini는 부족하면 하위모델( long context를 잘보는)로 라우팅 되는것 같아요
곧 GPT도 5.3 출시할텐데, 또 걔들은 얼마나 개선될지도 기대가 되는 포인트네요.
여러 곳에서 새로운 모델을 계속 출시하니까 모두 따로 구독하려면 비용이 꽤 많이 들지만 저는 10달러로 최신 모델 다 쓰게 해주는 사이트를 구독한 이후로 마음이 아주 편안해졌습니다.
https://www.clien.net/service/board/use/18918097?c=true#149343227CLIEN
제미나이 3.1 Pro도 나오자마자 바로 추가해주네요.
크레딧도 가격대비 넉넉하게 주는 편이고 크레딧 다 써도 제미나이3 플래시, 딥시크, GLM 같은 강력한 가성비 모델들을 무제한 무료로 쓰게 해줘서 든든합니다.