로컬 LLM 설치 후,
와 돌아간다~ 모먼트 이후
적당한 쓸모를 못 찾다가
예전에 만들어 올렸던 크롬 익스텐션이 생각이 나더군요.
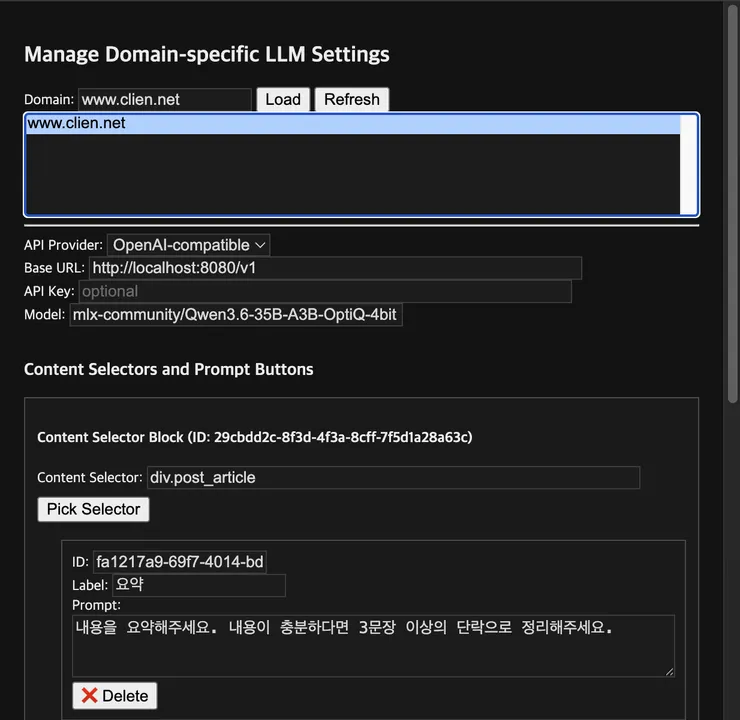
이 익스텍션이 기존에는 AI가 읽을 영역을 지정하려면 DOM 요소 식별자를 직접 입력해야 했습니다.
예를 들면 article, .content, #main 같은 걸 직접 찾아서 넣어야 했죠.
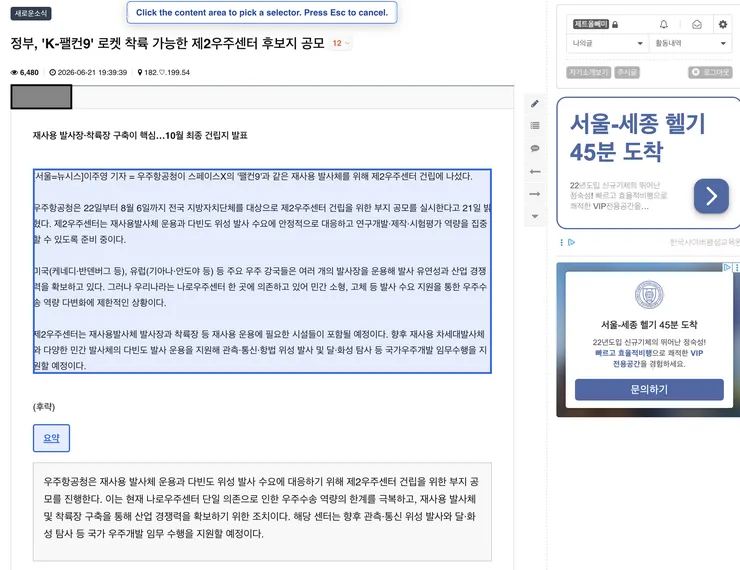
그런데 이번에는 마우스로 웹페이지의 원하는 영역을 클릭하면
자동으로 selector가 들어가도록 바꿨습니다.
- 뉴스 기사나 블로그 글을 엽니다.
- 확장 프로그램 설정에서 해당 도메인을 등록합니다.
Pick Selector를 누릅니다.- 웹페이지에서 AI가 읽을 본문 영역을 마우스로 클릭합니다.
- “요약하기”, “쉽게 설명하기” 같은 버튼을 만듭니다.
- 새로고침하면 본문 아래에 AI 버튼이 생깁니다.
사용 가능한 AI는 OpenAI, Gemini, Anthropic API도 되고,
Ollama 같은 로컬 AI 서버나 OpenAI-compatible 형식의 로컬 서버도 됩니다.
기능이 대단히 많은 건 아니지만,
드디어 로컬 LLM에게 줄 만한 현실적인 잡무를 찾은 것 같습니다.
어쨌든 쓸모입니다....( __)
맥북에어 사고 올라마 깔고 gemma4 설치후..오 빠르게 잘 돌아가네..
끝..
사용해보셨나요?! 후기가 몹시 궁금합니다!!
서빙모델을 어떤것을 사용하셨나요? 만약 Ollama 였다면 vLLM 이나
TRT 로 변경해보시면 체감속도가 확 올라갈겁니다.
Gamma 4 32B 나 Nemotron-3-nano 30B 등 28~36 사이에 모델을 돌리고 searxng/playwright 로 search, fetch mcp 구현해서 연동하면
결과도 좋고 꾸준히 50 tok/s 유지가 되더라고요.
거기에 더해서 LLM WIKI 까지 구축하면 꽤 품질이 좋아지죠.
vLLM 이나 TRT 이기 때문에 배치로 멀티 요청하는것도 꽤 안정적으로 처리를 해주고요.
그냥 api 돈내고 말지…
모든 Use Case를 충족하는 로컬llm은 불가능하지
않을까요? 가능하더라도 비용을 생각하면…