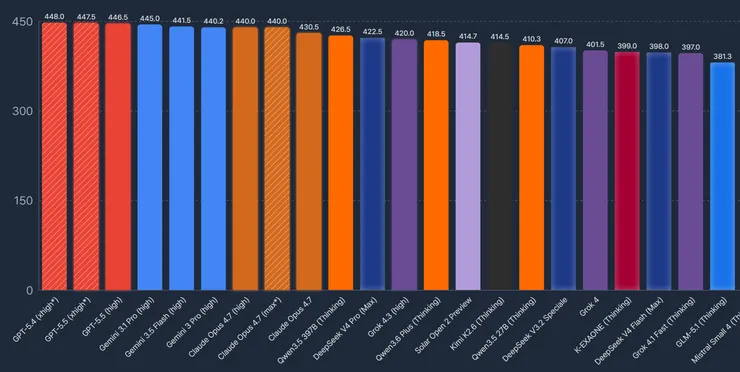
수능에는 다방면의 지식과 추론이 필요하므로 꽤 유용한 벤치라고 볼 수 있습니다.
페이블5나 오푸스 4.8이 빠져 있음을 감안해서 보시고,
그 와중에 업스테이지의 솔라 프로4(오픈2) 프리뷰의 성능이 1T나 되는 KIMI2.6을 넘어서고,
Qwen3.6 Plus(씽킹)의 바로 다음 순서인 것을 보면,
기대한 이상의 점수가 나왔다고 볼 수 있겠습니다.
독자 파운데이션 모델에 대해 비관적으로 이야기 하시는 분들이 꽤 있었습니다만,
GPU가 쥐뿔도 없던 시절에도 꽤 준수한 성적을 냈었는데,
지원이 잘 될 때 더 못할 이유가 있겠느냐고 말씀드린 적이 두어 차례 있었습니다.
프런티어에 비해 부족하나 가진 여건을 감안하면 엑사원과 솔라는 괜찮은 성적이었습니다.
다만 눈 높이가 올라간 시점에서 사용해 보면...개인 사용으로도 만족이 어려웠습니다.
또한 프런티어 모델은 비단 답변 성능만이 아니라
장기 컨텍스트 활용시 성능 유지력 등 보이지 않는 영역을 아우르고 있습니다.
조만간 테스트를 지나 정식 오픈이 되면 아무래도 프리뷰 버전에서 지적 된 부분이 개선 되어 나온다고 가정해보면,
독파모로서의 역할은 기대해 볼 수 있을 듯 합니다.
참고로 상업 서비스용은 프로4로 오픈 모델로는 오픈2로 명명 되어 나오는 것 같습니다.
다만, 이제는 저런 테스트는 기초체력 테스트로 보여서... 성능을 판단하기에 충분히 좋은 테스트는 아니라고 생각합니다.
요즘 LLM 모델의 사용환경은 대부분 Agentic Use를 가정하고 있는 상황인지라....
아시는 분들은 아시겠지만 그 똥같은 Gemini가 저렇게 고평가 받는거만 봐도 테스트의 신뢰성이... 음..
Artificial Analysis Intelligence Score 정도가 빨리 업데이트 되었으면 좋겠네요.
2. 솔직히 독파모 자체의 의의에 대해서는 공감하고, 필요한 사업이라고 봅니다.
다만, 여전히 미국 > 3~6개월 > 중국 > 3~6개월 > 독파모 정도 간격이 떨어져 있어서... 아마 이번에 나올 모델은 올 초~중반에 나온 Qwen 3.5 수준과 3.6 수준 사이를 예상합니다. 이 정도만 되어도 의의는 충분히 있고, Fable 사태를 보듯 국가적으로 모델 역시 전략 자산이니 더 나은 소버린 모델은 분명 필요하겠죠.
빠르게 독파모가 중국 근처까지 추격했으면 좋겠네요.
음... 그게 테스트 해볼 수 있는 기회를 얻은 사용자들이 있고,
그래서 저 위에 테스트결과도 나온 것인데요.
사용해 본 사람들이 하는 말을 보면... 좀 기대해 봐도 될 것 같아서 적어 본 글입니다. ㅎㅎ
수능의 경우...뭐랄까....요즘 육손이나 세차장처럼 새 모델 나오면
한 번씩 거치는 ... 통과의례처럼 되었습니다.