컨텍스트 윈도우의 처리는 코딩에 있어서 어지간한 아주아주 간단한 앱을 제외한...
일반적 규모 이상의 대부분의 경우에서,
이 컨텍스트를 어떻게 다룰 줄 아는가가 실제 체감 성능과 직결되어 있습니다.
그리고 이 컨텍스트 처리가 AI기업의 경쟁력이기도 하며, 비용 증가의 주범이기도 합니다.
브레인스토밍의 경우도 질문 한 두 번에 결과물을 내면 덜하겠지만,
여러 질문을 꼬리에 꼬리를 물어 가며 마치 정리 된 논문을 쓰듯이 딥 리서치를 할 때라면,
각 질문과 질문간의 답을 제대로 이해하고 관계 되는 사고를... 잘 하는가가 지능과 연관 됩니다.
즉, 데이터간의 상관 관계를 평면적으로 하는 것이 아니라 깊은 추론까지 되는 것이 AI의 지능이고,
이 부분에서 가장 잘하는 곳이 오픈AI의 챗지피티입니다.
그래서 지능 관련 테스트를 하면 챗지피티5.5가 거의 대부분의 벤치에서 1위를 하며,
새로 나오는 보다 다듬어진 벤치에서는 거의 항상 1위를 합니다.
그런데, 실제 작업 환경에서 오푸스가 더 낫다는 말이 많은 것은
이렇게 인공지능이 복잡한 사고를 할 수 있는 컨텍스트를 길게 유지하고 그 안에서 사고 하는 점에서 더 뛰어나기 때문으로...
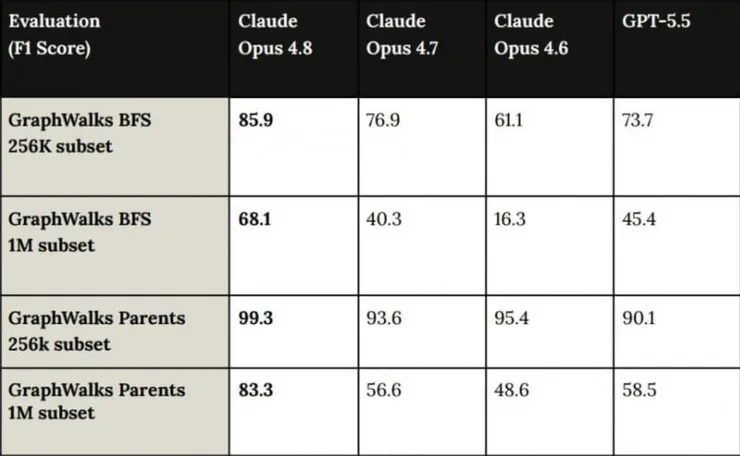
위 그림의 '롱 컨텍스트' 처리에 관한 성능에서 왜 그러한 차이가 만들어 지는 지 알 수 있습니다.
예를 들어 중간 규모의 앱을 개발 할 때...어떤 오류를 잡아 낼 때 빠짐 없이 잡아 내려면,
이 컨텍스트 윈도우 내의 처리를 정확하게 처리 할 수 있어야 하므로,
어지간한 작업 대부분의 경우 클로드가 우세일 수 밖에 없습니다.
게다가 이번에 4.8버전은 이와 관련된 성능이 크게 점프했습니다.
고무적인 일이 아닐 수 없네요.
업무에는... 당분간... 클로드가 가장 좋을 수 밖에 없어 보입니다.
성능이 좋다고 약팔면 뭐하나요. 하드웨어 케파 부족하다고 말없이 성능 다운시키고, 다음버전 나오기 직전에 성능다운 시키면 실 사용자 입장에서는 한두세대 전버전 쓰는거랑 동일한 사용감입니다.
스페이스X의 콜로서스를 대여하게 되었으니... 상황이 많이 나아질 것 같습니다.
프롬프트 출력해서 비교해보고 있는데 좀 그러네요
토큰 소모는 좀 줄어 든거 같긴 합니다. 어차피 마이너 업데이트니까 제자리 돌아온 느낌이랄까요.
4.7이 너무 심각해서 못쓸수준이여서
아직은 gpt 5.5가 주력입니다
4.8도 말을 잘 못알아듣고 자꾸 물어요
ㅜㅜ
코딩에서 클로드의 문제는 환각에 의한 <허위보고와 잘못된 와이어링> 인데, 4.8 에서 그 빈도 역시 줄어든 것을 체감합니다. (체감상 20~30% 정도 감소...)
다만, 그래서 코딩 관련한 작업과 보고, 주장 전체를 믿고 넘어가도 될 수준인가 냐고 하면 아직도 타 모델에 의한 재검수 없이는 불가 상태로 봐야 합니다.
Opus 4.8 은 모델 자체의 성능 변화는 미미하지만, 하네스의 수정 및 업데이트로도 큰폭의 변화를 줄 수 있음을 증명한 좋은 예라고 생각됩니다.