
LGAI-EXAONE/EXAONE-4.5-33B · Hugging Face
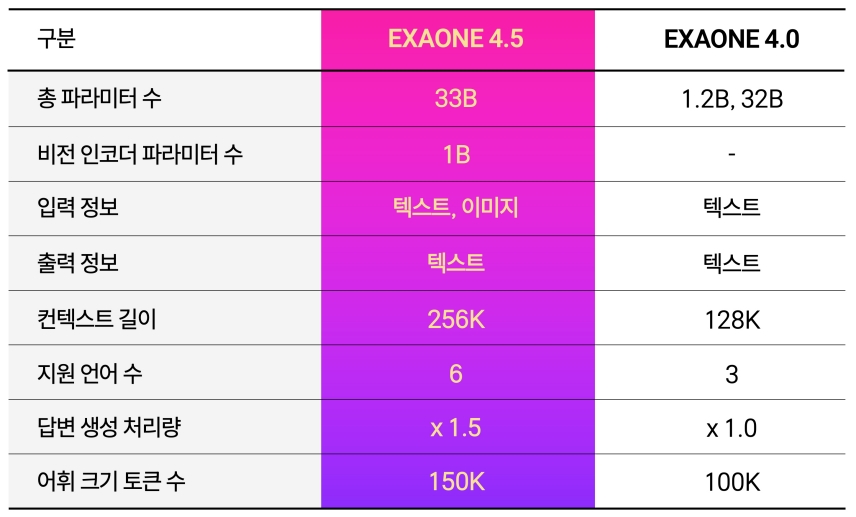
LG의 첫 공개 Vision Language Model, EXAONE 4.5
LG AI연구원이 EXAONE 4.5를 새롭게 선보입니다. EXAONE 4.5는 LG 최초로 오픈 웨이트(open-weight)방식으로 공개하는 비전-언어 모델(Vision Language Model, VLM)입니다.
기존 EXAONE 4.0의 언어 처리 중심의 구조에서 나아가, 자체 개발한 시각 인코더(Visual Encoder)를 혁신적인 모델 구조에 통합했습니다. 이를 통해 텍스트는 물론, 이미지와 같은 시각 정보까지 동시에 이해하고 처리할 수 있는 진정한 멀티모달(Multimodal) 모델로 거듭났습니다.
이러한 확장을 위해 EXAONE 4.5는 텍스트와 시각 정보를 처음부터 함께 학습하는 네이티브 멀티모달 사전학습(Native Multimodal Pretraining) 방식을 택했습니다. 시각과 언어 모듈을 각각 학습한 뒤 단순 결합하거나 후처리하는 방식과 달리, 처음부터 두 가지 정보가 자연스럽게 융합되도록 설계하여 멀티모달 이해 능력을 극대화했습니다.
또한, 언어와 비전 두 영역 모두에서 균형 잡힌 최고 수준의 성능을 달성하고자 방대한 규모의 데이터로 학습을 진행했습니다. 특히 실제 산업 현장에서 수요가 높은 STEM(Science, Technology, Engineering, Mathematics) 영역과 문서 이해(Document Understanding) 영역에 집중하여, 데이터 수집부터 정제, 가공에 이르는 각 단계를 체계적으로 수행했습니다. 그 결과, 글로벌 범용 벤치마크에서 경쟁력 있는 성능을 기록했으며, 복잡한 문서 기반 작업과 한국어 및 한국의 시각적 맥락 이해에서도 강점을 발휘합니다.
1. 모델 구조 설계
EXAONE 4.5 개발의 핵심은 언어 모델의 능력을 시각 영역으로 자연스럽게 확장하는 것이었습니다. 이를 위해 모델 구조 자체를 새롭게 설계했으며, 아래에서 EXAONE 4.5를 구성하는 기술적 기반과 추론 속도 개선 작업에 대한 핵심 요소에 대해 소개합니다.
1.1 Visual Encoder가 통합된 모델 구조
EXAONE 4.5는 LG AI연구원의 독자적인 거대언어모델(LLM)인 EXAONE 4.0에 자체 고안한 Visual Encoder를 통합한 구조로 설계됐습니다. 통합 과정에서 가장 중점을 둔 것은 시각 정보 처리로 인한 연산량 증가를 최소화하고, 실제 서비스 환경에서의 추론 속도를 확보하는 것이었습니다. 이를 위해 추가된 Visual Encoder 내부의 어텐션 메커니즘에 Grouped Query Attention (GQA) 방식을 택했습니다.
GQA는 어텐션 연산에 사용되는 쿼리(Query)를 여러 그룹으로 묶고, 각 그룹이 동일한 키(Key)와 값(Value) 헤드를 공유하는 구조입니다. 모델 성능을 유지하면서도 연산량과 메모리 사용량을 줄일 수 있다는 점에서 실용적인 선택이었습니다. 또한 대다수의 최신 추론 프레임워크(vLLM, TensorRT-LLM, SGLang 등)가 GQA 기술을 기본적으로 최적화하여 지원하고 있어, EXAONE 4.5를 활용하는 개발자들은 별도 작업 없이도 하드웨어 자원 사용을 효율적으로 활용한 추론 속도를 그대로 경험할 수 있습니다.

이미지 1. EXAONE 4.5 모델 구조도
1.2 멀티 토큰 예측을 통한 추론 속도 개선
텍스트 생성 단계에서는 멀티 토큰 예측(Multi-Token Prediction, MTP) 모듈을 새롭게 도입해 EXAONE 4.0 대비 모델 추론 속도를 개선했습니다.
기존 언어 모델들은 한 번에 하나의 토큰만 예측하고, 그 결과를 다음 예측에 순차적으로 반영하는 자기회귀(Autoregressive) 디코딩 방식을 사용해 왔습니다. 구조가 직관적이라는 장점이 있지만, 매번 단일 토큰을 생성할 때마다 전체 모델의 연산을 거쳐야 하므로 추론 속도와 컴퓨팅 효율성 측면에서 한계가 존재했습니다.
MTP는 단일 토큰을 넘어, 다음 토큰과 그다음 토큰까지 예측하고 생성합니다. 이를 통해 기존 대비 추론 속도를 약 1.5배 이상 향상시켰으며, 실제 서비스 환경에서 사용자가 체감하는 응답 속도로 개선됩니다.
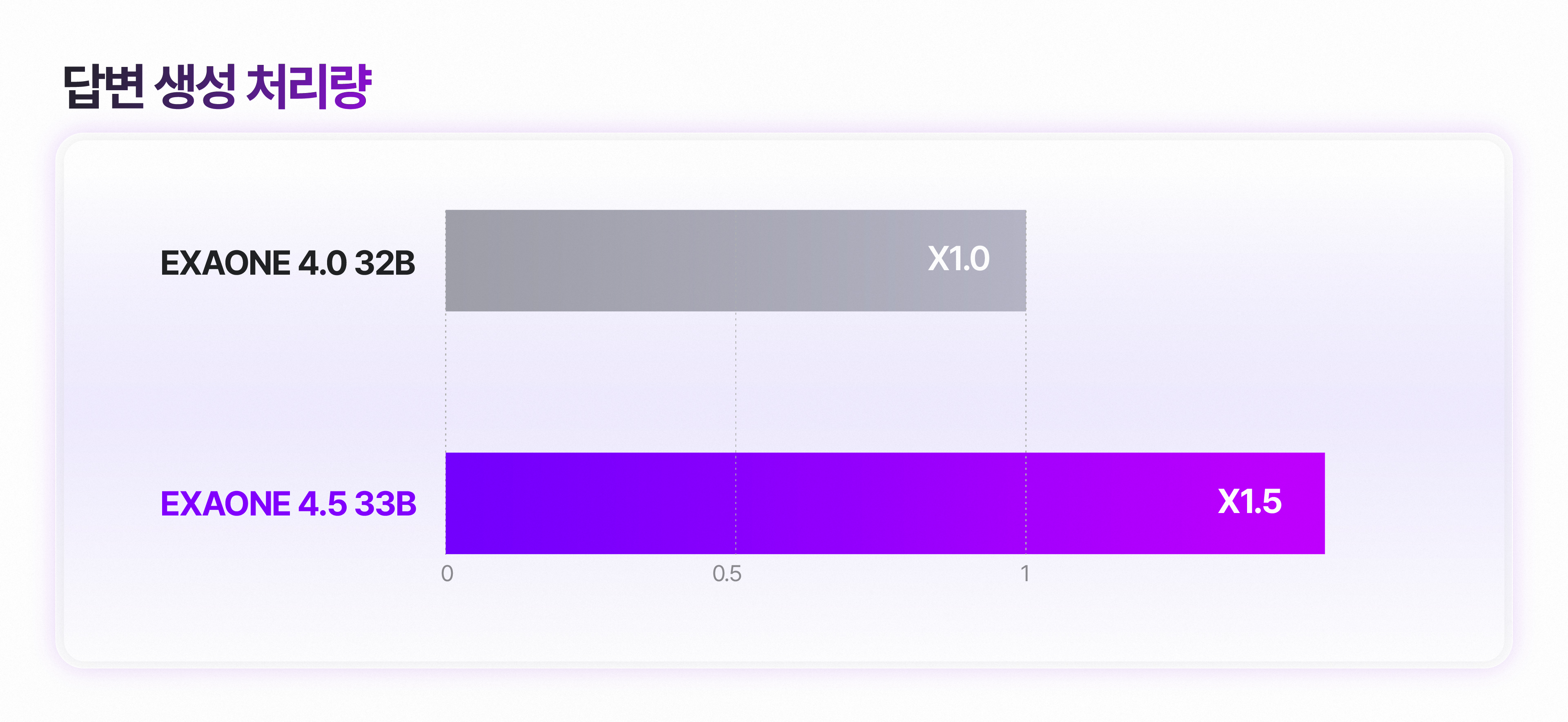
이미지 2. EXAONE 4.5 답변 생성 처리량
2. 모델 학습
EXAONE 4.5의 학습은 크게 방대한 지식을 흡수하는 사전학습(Pre-training)과 실제 활용 목적에 맞게 모델을 다듬는 사후학습(Post-training)의 두 단계로 진행됐습니다.
2.1 사전 학습
EXAONE 4.5의 사전학습은 텍스트 중심의 지식 학습과 시각 정보를 아우르는 멀티모달 학습을 병행했습니다. 기초 지식과 전문 지식, 추론 능력을 갖추기 위해 텍스트로 구성된 대규모 데이터를 학습하는 과정과 모델이 텍스트와 이미지를 경계 없이 이해할 수 있도록 사전학습 과정에 시각 정보를 자연스럽게 녹여내는 네이티브 멀티모달 사전학습(Native Multimodal Pretraining) 방식을 적용했습니다.
이번 사전학습의 핵심은 추론 능력의 근본적인 강화였습니다. 이를 위해 사고 궤적(Thinking Trajectory)을 포함한 고품질의 데이터를 합성하여 학습에 활용함으로써, 모델이 최종 정답만을 도출하는 것에 그치지 않고, 단계별 사고 과정을 스스로 학습하도록 설계했습니다. 복잡한 문제를 해결할 때 어떤 논리적 흐름을 따라가야 하는지, 그리고 어떤 중간 단계를 거쳐야 하는지를 모델의 기저에 각인시킵니다. 이러한 사고 궤적 중심의 학습 방식은 이후 이어지는 사후학습 단계에서 모델의 논리적 추론 및 문제 해결 능력을 향상시키는 핵심적인 기반이 됐습니다.
2.2 사후학습
사후학습은 방대한 지식을 갖춘 모델이 사용자의 의도를 정확히 파악하고, 유용한 답변을 제공할 수 있도록 정렬(Alignment)하는 과정입니다. EXAONE 4.5의 사후학습은 지도 미세조정(SFT)과 강화학습(RL), 두 단계로 진행됐습니다.
SFT 단계에서는 사용자가 마주할 수 있는 수많은 시나리오를 포괄적으로 커버하기 위해, 다양한 도메인의 데이터셋을 대용량으로 수집하고 가공했습니다. 특히 실제 비즈니스 환경에서 수요가 높은 문서 영역의 데이터 구축에 집중했습니다. 복잡한 표, 수식, 다단 레이아웃 등이 포함된 산업용 문서들을 모델이 정확하게 인식하고 분석할 수 있도록 특화 데이터를 구축해 기업 환경에서의 실용성을 높였습니다.
SFT 이후 진행된 강화학습(RL) 단계에서는 LG AI연구원이 자체 고안한 AGAPO 알고리즘을 도입했습니다.
일반적인 최신 강화학습 알고리즘은 모델이 생성한 답변 샘플이 모두 오답일 경우, 적절한 학습 신호(Advantage)를 계산하지 못해 해당 데이터를 버리는 한계가 있었습니다. 반면, AGAPO 알고리즘은 오답 속에서도 학습의 신호를 찾을 수 있도록 설계되었습니다.
-
비대칭 샘플링(Asymmetric Sampling): 모두 오답인 샘플 그룹을 버리지 않고, 오답의 원인이 되는 잘못된 추론 경로에 페널티(Negative Reward)를 부여해 모델이 논리적 오류를 스스로 피하도록 유도합니다.
-
안정적인 이점 계산(Group & Global Advantages): 개별 응답 그룹(Group) 내부 평가와 전체 배치(Global Batch) 단위의 데이터 분포를 두 단계로 고려해 보상을 계산함으로써 학습의 안정성을 높였습니다.
-
탐색적 토큰 보존: 기존 알고리즘에서 학습 안정성을 위해 적용하던 클리핑 (Clipping) 제약을 해제해, 복잡한 추론 과정에서 분기점이 되는 탐색적 토큰(Exploratory Tokens)들이 학습에서 누락되지 않도록 보호합니다.
AGAPO 알고리즘의 적용을 통해 EXAONE 4.5는 논리적 추론 능력을 강화하는 동시에, 학습 효율도 확보했습니다.
3. 성능 평가
비전-언어 모델(VLM)의 성능은 단순히 이미지 속 객체를 인식하는 것을 넘어, 시각 정보와 텍스트 문맥을 논리적으로 연결하고 복잡한 추론을 수행하는 능력을 종합적으로 평가해야 합니다. 학계와 산업계에서는 대학 수준의 전문 지식, 수학적 추론, 시각적 질의응답(VQA) 등 다양한 난이도와 도메인을 포괄하는 표준 벤치마크를 활용합니다.
EXAONE 4.5의 성능 검증을 위해, 현재 글로벌 시장에서 주목받는 주요 오픈 웨이트 및 상용 VLM들과 비교 평가를 진행했습니다. Vision 분야에서는 Qwen 3.5 27B, Qwen 3 VL 235B-A22B, Qwen 3 VL 32B, Claude Sonnet 4.5, GPT5-mini 모델을 비교 대상으로 설정했고, Text 및 Agent 분야에서는 전작인 EXAONE 4.0 32B와 K-EXAONE 236B 모델을 비교 모델로 선정했습니다.
3.1 범용 VLM 성능 평가
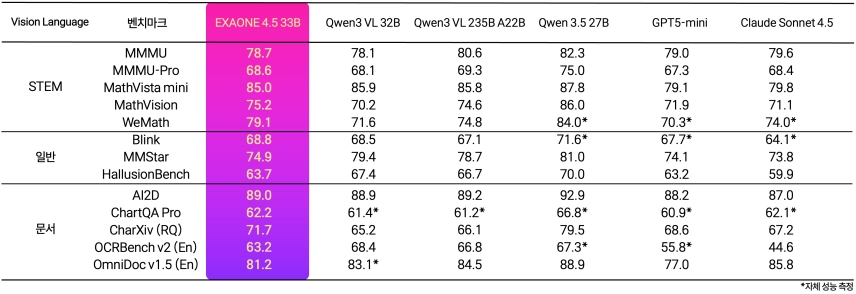
비전-언어 모델(VLM)이 실제 산업 현장에 도입되기 위해서는 단순한 이미지 인식 수준을 넘어, STEM(과학·기술·공학·수학) 기반의 시각적 추론 능력과 전문적인 문서 이해 능력이 필수적입니다. 표 1은 시각 문서 이해와 관련된 주요 벤치마크에 대해 EXAONE 4.5와 비교 모델들의 성능을 정리한 결과입니다.
-
종합 영역에서의 시각적 추론: 종합 영역에서의 추론을 요구하는 MMMU-Pro에서는 GPT5-mini와 Claude Sonnet 4.5를 상회하며, 전문가 수준의 지식 처리에서도 주요 상용 모델의 성능을 넘어설 수 있음을 보여주었습니다.
-
수학 영역에서의 시각적 추론: 시각적 수학 문제 해결 능력을 평가하는 MathVision, WeMath, LogicVista 벤치마크에서 Qwen 3 VL 32B는 물론, Qwen 3 VL 235B도 앞섰습니다. 상용 모델인 GPT5-mini와 Claude Sonnet 4.5와 비교해서도 대부분의 항목에서 우위를 보였습니다.
-
학술 및 차트 분석: 차트와 다이어그램 이해도와 추론 역량을 요구하는 CharXiv (RQ)에서 Qwen 3 VL 32B와 GPT5-mini, Claude Sonnet 4.5를 모두 큰 차이로 앞섰습니다. 또한 ChartQA Pro와 다이어그램 이해 능력을 평가하는 AI2D에서도 우수한 성적을 기록했습니다.
-
텍스트 추출: 광학문자인식(OCR) 및 문서 이해 능력을 평가하는 OCRBench_v2 및 OmniDoc_v1.5에서도 GPT5-mini 등 일부 상용 모델을 상회했으며, 실무 적용 가능성을 보여주었습니다.
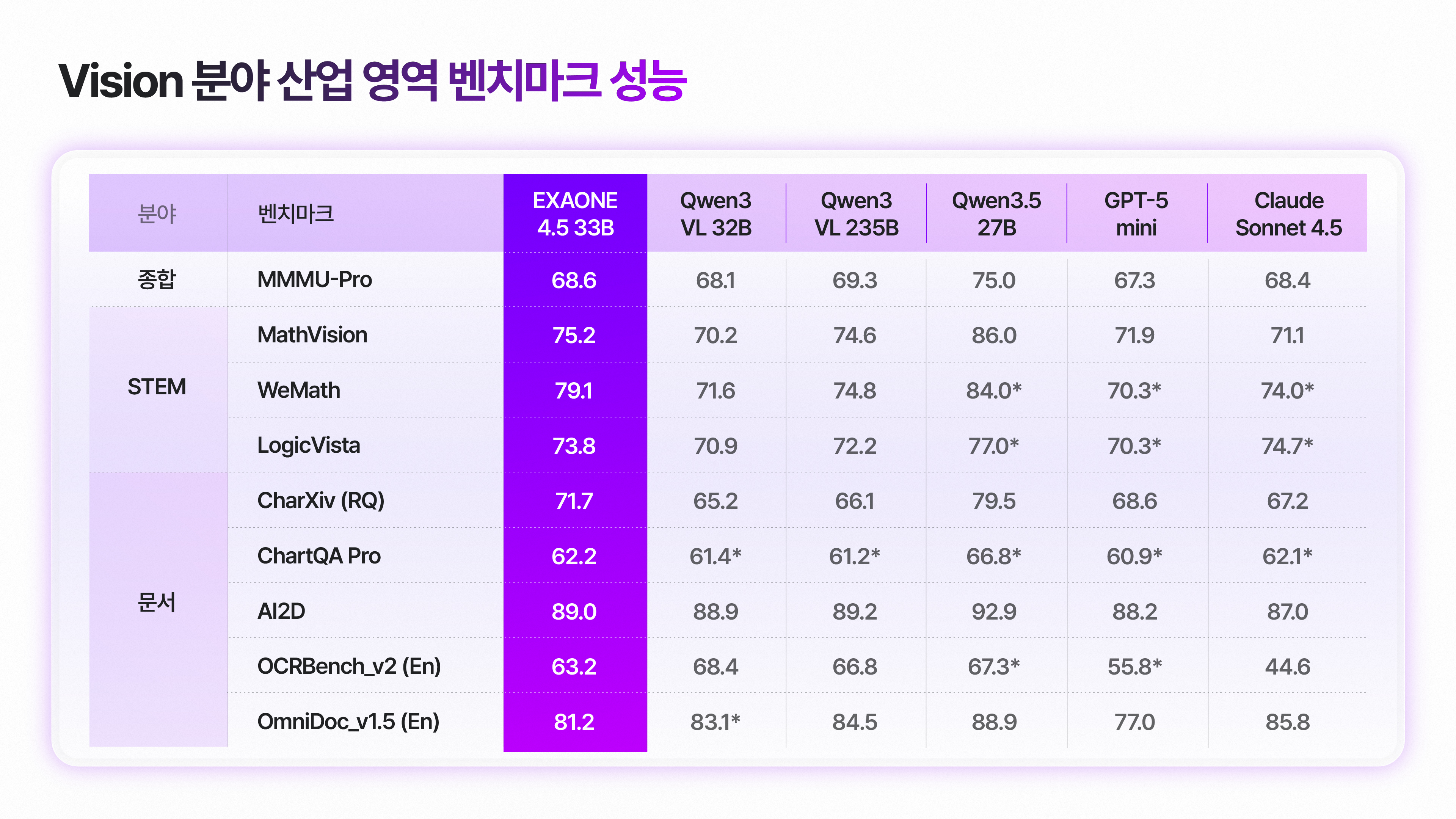
이미지 3. Vision 분야 산업 영역 벤치마크 성능
3.2 일반 영역에서의 Vision 분야 성능 평가
EXAONE 4.5는 전문 및 문서 영역에 특화되어 있으면서도, 일상적인 시각 정보 처리와 한국 문화가 반영된 벤치마크에서도 글로벌 주요 상용 모델들과 대등하거나, 그 이상의 성능을 보입니다.
-
시각 추론: 다양한 시각적 과제를 종합 평가하는 Blink 벤치마크에서 Qwen 3 VL 32B, Qwen 3 VL 235B는 물론, 상용 모델 대비 성능 우위를 확인했습니다. 또한, MMStar 벤치마크에서도 상용 모델을 상회하는 범용 시각 이해 능력을 기록했습니다.
-
환각 억제: 시각적 환각을 측정하는 HallusionBench에서 상용 모델들보다 높은 점수를 달성했습니다.
-
한국형 시각-언어 이해: 한국 특화 시각-언어 벤치마크인 k-viscuit과 KRETA에서 Qwen 3 VL 32B 대비 우수한 성능을 나타냈습니다.
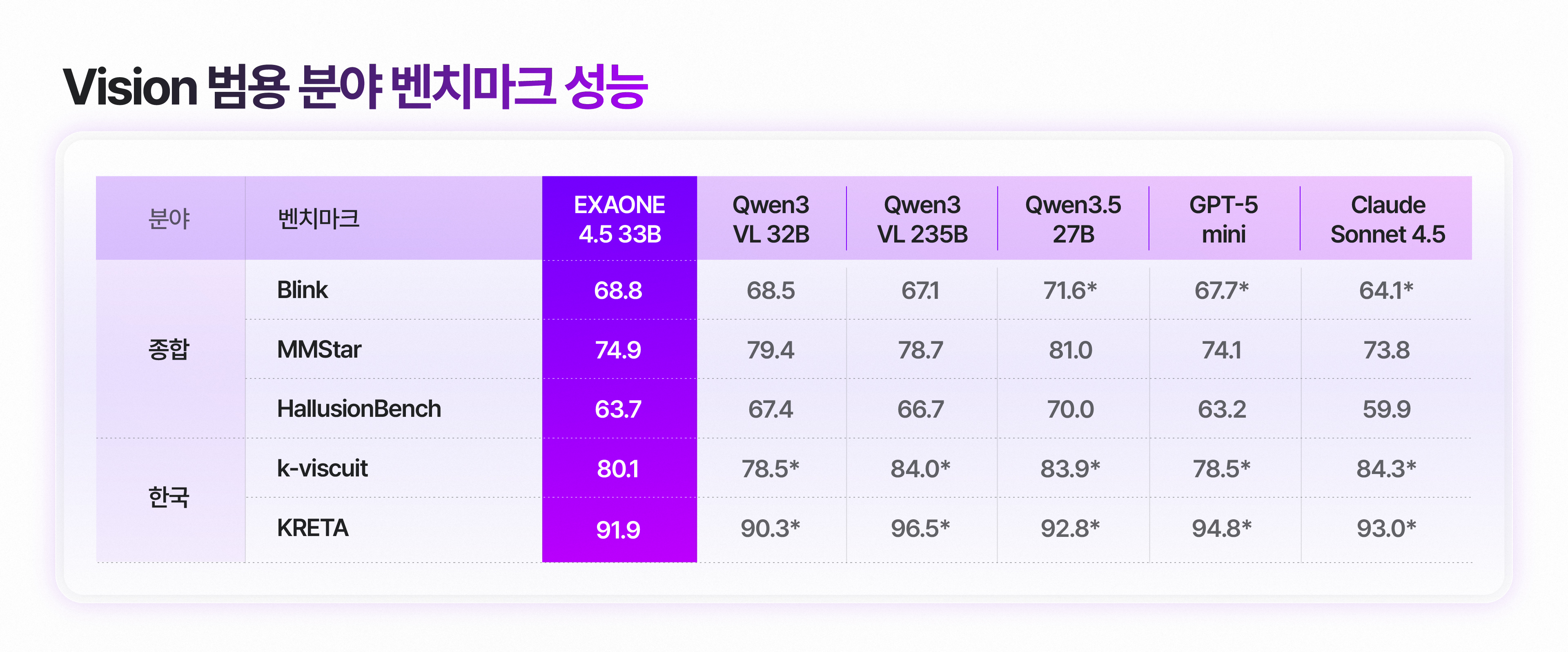
이미지 4. Vision 범용 분야 벤치마크 성능
3.3 Text 및 Agent 영역에서의 성능 평가
마지막으로 EXAONE 4.5의 Text 추론 및 Agent 역량에 대한 성능 평가 결과입니다. 이번 모델은 전작인 EXAONE 4.0은 물론, 훨씬 더 큰 파라미터 규모를 가진 K-EXAONE과 비교해도 대등하거나 그 이상의 성능을 달성했습니다.
-
종합 영역에서의 추론: 종합 영역에서의 추론을 요구하는 MMLU-Pro에서 EXAONE 4.0 대비 성능 우위를 확인했으며, K-EXAONE과도 필적하는 수치를 달성하였습니다.
-
수학 및 과학 추론: 수학적 사고력을 측정하는 AIME25와 전문가 수준의 지식 추론 능력을 평가하는 GPQA-D 모두에서 K-EXAONE을 소폭 앞섰습니다.
-
프로그래밍: 코딩 능력을 측정하는 LiveCodeBench v6에서도 K-EXAONE 점수를 상회하며, 복잡한 알고리즘 구현과 코드 생성 능력에서 전작 대비 개선된 모습을 확인할 수 있습니다.
-
Agent: 도구 사용 능력을 평가하는 Tau2 벤치마크에서 EXAONE 4.0 대비 큰 폭으로 향상되었습니다. 복잡한 워크플로우를 이해하고 실행하는 에이전트로서의 활용 가능성을 보여줍니다.
-
지시 이행: 사용자의 복잡한 제약 조건을 준수하는 능력을 보여주는 IFBench와 IFEval 역시 전작 대비 눈에 띄게 개선되었습니다. 실제 산업 현장에서 요구되는 복잡한 조건과 까다로운 가이드라인을 정교하게 따를 수 있게 되었습니다.
-
장문 문맥 이해: 긴 문맥의 이해도를 평가하는 AA-LCR에서 전작 대비 3배 이상 향상되었으며, K-EXAONE 성능에 필적하는 수준입니다. 상대적으로 가벼운 모델로도 대규모 문서 처리가 가능합니다.
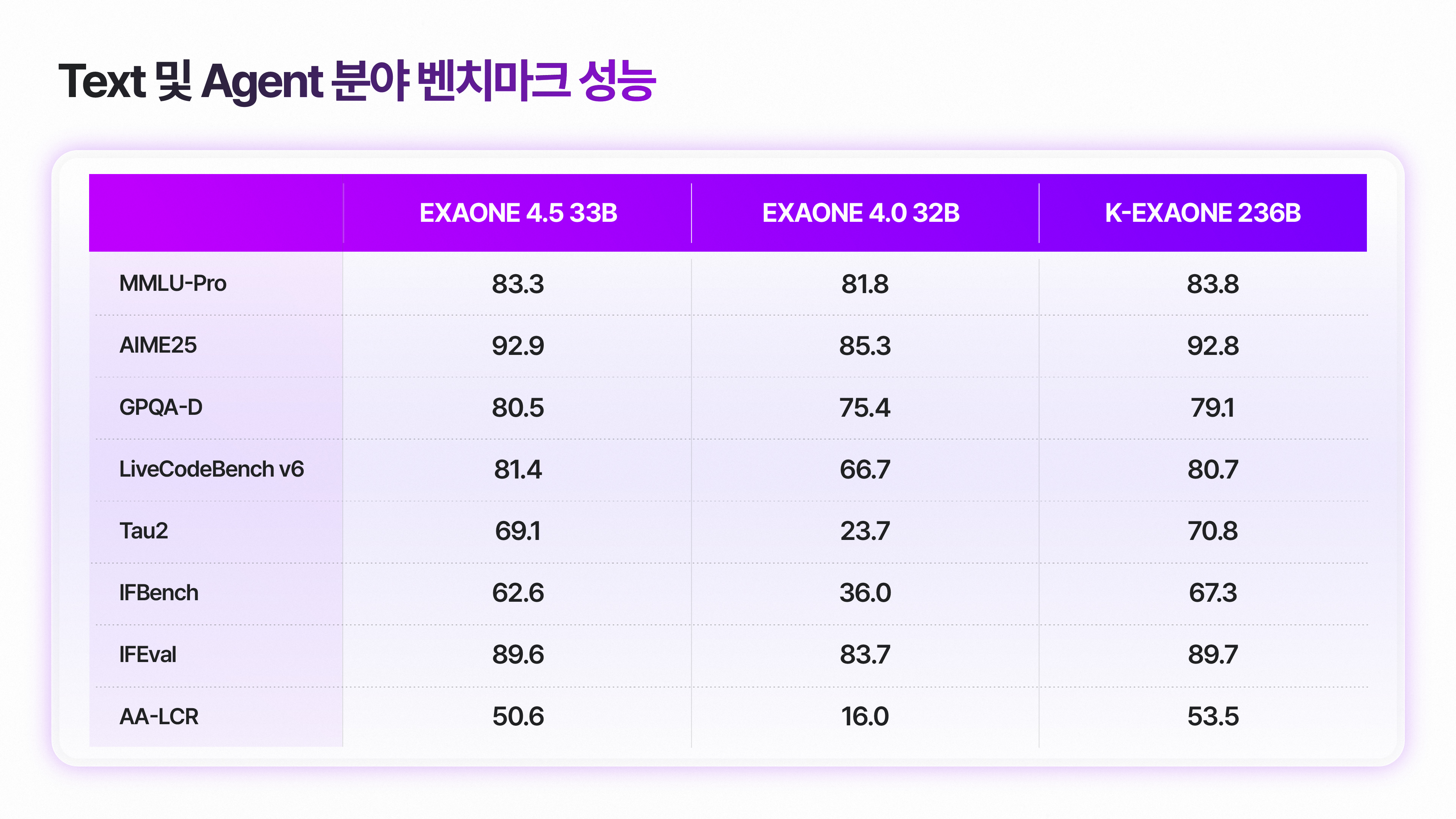
이미지 5. Text 및 Agent 분야 벤치마크 성능
4. 마무리
EXAONE 4.5는 언어와 시각의 경계를 허물고, AI가 실제 산업 현장에서 작동하는 방식을 한 단계 넓힌 모델입니다. 이번 오픈 웨이트 모델 공개가 전 세계의 연구자 및 개발자 생태계 활성화에 기여하길 기대합니다. 연구 개발과 파트너십을 통해 끊임없이 도전하고 진화해 나갈 EXAONE의 다음 여정에도 많은 관심 부탁드립니다.
컨텍스트도 256K면 실작업엔 살짝 아쉽지만 not bad인 것 같고..
33b 정도 로컬에서 돌릴 pc가 있으면 좋겠는데 ... 너무 비싸네요. ㅎㅎ
수치를 보면 Qwen3.5 27B가 괴물이군요.
ollama나 LMstudio에서 다 설치가능합니다. 4.5는 아직 안올라와 있지만, 4.0 1.2B 엄청 빠릿빠릿하고 괜찮던데요.