예전에도 한 번 올렸었는데요.
실감을 잘 못하는 것 같아 재 추천합니다.
로컬의 성능에 회의적인 시각을 가졌다면... 다음을 보시죠.
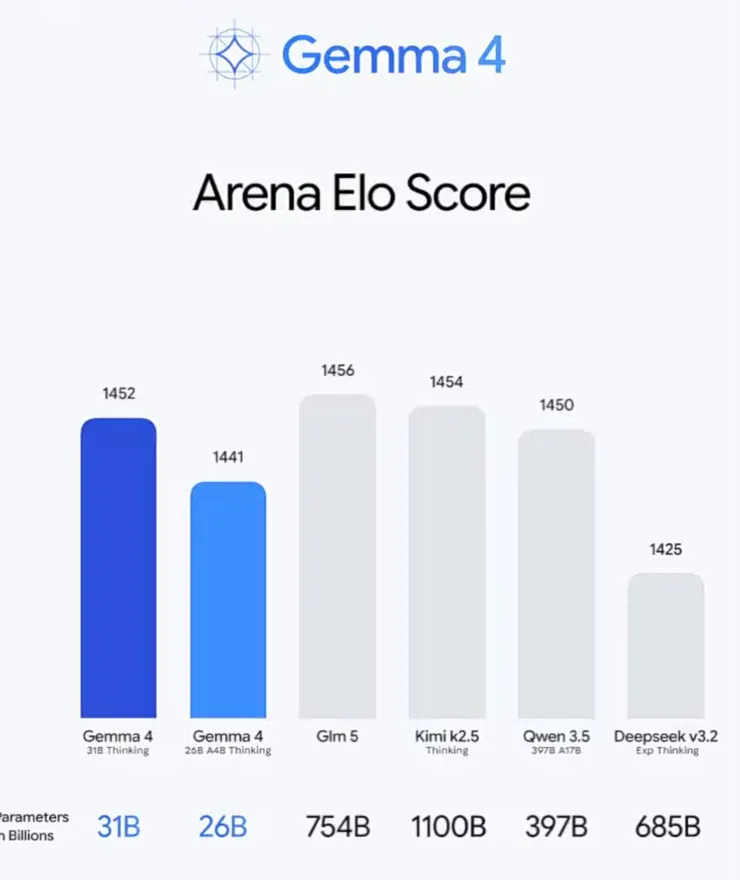
10배 큰 공개 모델과 비슷하거나 윗급입니다.
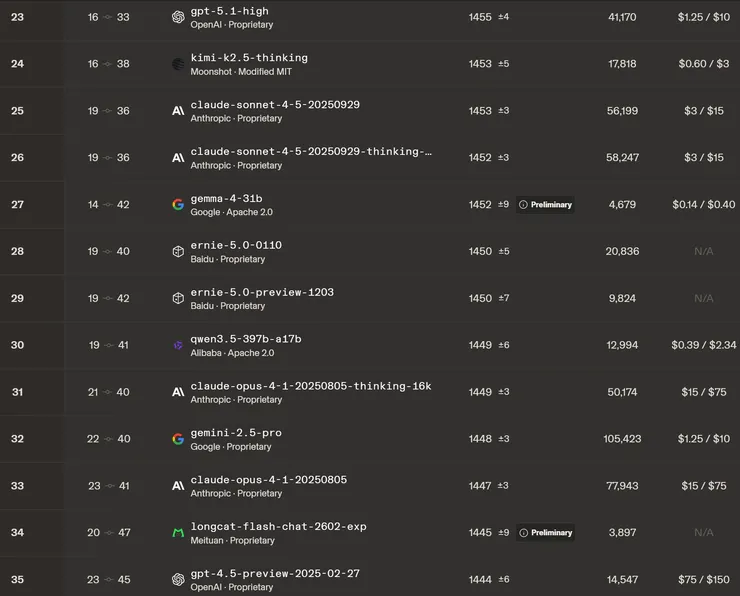
젬마4-31B는 제미나이 2.5프로 보다 위고, 지피티 4.5 프리뷰 보다 위에 있습니다.
심지어 Qwen3.5-397b 보다도 위에 있습니다.
젬마4의 윗급을 보면 더 실감납니다.
바로 위에 클로드 소넷 4.5 ... 씽킹이 있습니다. 씽킹이 들어가야 사실상의 동급입니다.
작은 파라메터 안에서의 성능 향상은 이제 거의 팔부 능선은 넘은 것 같습니다.
기존의 아키텍쳐에서 달라진 것은 거의 없는 대신
학습 데이터 등에 신경 쓴 결과가 이러합니다.
제가 제미나이 2.5 프로 나올 무렵에 했던 주장이 있습니다.
바로 소버린 AI가 이 정도 성능이 되어야 나름 의미가 있다는 내용이었습니다.
바꿔 말하면 이 이하로는 사실 공짜로 쓰라고 해도 잘 안 써진다는 말입니다.
잠깐은 써도 업무에 활용하려면...
이제 드디어 오픈 소스 진영의 모델이 과거 프런티어 수준이면서
사용자의 체감을 좋게 하는 일정 선을 넘어갔습니다.
특히 한국어 및 여러 언어를 잘 쓰는 점이 체감 성능 평가에서 좋은 점수를 받은 듯 합니다.
31b 직접 써 보니 '쓸만하다'의 선을 최초로 넘은 개인 PC용 로컬 모델입니다.
특히, 저처럼 검열을 싫어하는 분들에게는 최고의 선택(heretic ara 양자화 추천)입니다.
저는 탭을 수십개씩 막 켜놓고 동시에 돌리는 중인데 RAM 50G, VRAM 23G 정도 사용하네요.
찾아보니, 쾌적하게 쓰려면 사양 좋은 그래픽카드 붙어있는 피씨가 유리하겠네요.
램도 그렇고, 다다익선이 적용되는 사례라, 최저사양은 답변을 기다리는 시간이 좀 오래 걸리겠죠.
유튜브에 올라온 후기를 보니, M4맥북으로 돌리는 분들 있던데, 풀가동하느라 하판이 뜨뜻해진다는데요. 아무래도, 일반적인 피씨작업에 비해서 연산을 많이 하니, 노트북같은 경우는 지속적으로 발열이 발생할 거 같단 생각이 드네요. 로컬모델에 거, 생각 깊게 하는 모드로 질문하면 답변에 따라 일이십초 혹은 그 이상 걸리기도 하던데요.
24기가 기준이면 양자화해서 8B 모델로 내려가야 하는 것 같습니다.
그래도 Gemma가 바로 맥기준으로 돌아가게 만든 것 자체가 대단한 것 같습니다.
https://wikidocs.net/blog/@jaehong/10624/
현실은 맥미니가 24gb 램이라....ㅜㅜ
(메모리는 24기가 거의 근접에서 사용되고, 팬이 아주 크게 돌아갑니다. )
아래와 같이 동작을 잘하긴 하네요.
다른 추가 애플리케이션은 돌릴수도 없겠네요;;
양자화 모델로 돌리시면 됩니다.
31B가 벤치 점수 차이 보다 실 체감에서 더 좋기 때문에 31B로 보세요.
26B가 속도는 더 빠르지만 체감 성능은 좀 차이가 있습니다.
로컬 지식면에서 좀 부족한 게 있어도 그런 건 요새 RAG 붙여서 해결하니까 문제는 아닐 거고..
이제야 로컬 LLM으로도 일정 수준의 threshold를 넘은 제품이 나왔다고 생각해도 괜찮으려나요 ㄷㄷ
정확히 하자면,
깊은 추론 및 코딩 쪽에서 Qwen 대비 밑입니다.
그 외의 사무 용도에서, 한국어에서, 종합적으로 더 좋습니다.
딥 추론이 필요한 경우 Qwen이 낫습니다.