구글 주요 임원들이 이런 트윗을 올리는 것을 보니,
제미나이의 출시가 임박한 것으로 보입니다.
아래는 공개된 제미나이의 핵심 정보와 벤치마크 자료입니다.
참고하시기 바랍니다.
빨리 출시되길 기대하며, 빨리 활용하고 싶습니다.
어플 만들고 있고, 개인적으로 책 쓰고 있는데,
3.0 프로 빨리 활용하고 싶습니다~~

구글, <제미나이3 프로> 공개
= '희소 혼합 전문가(Sparse MoE)' 트랜스포머 기반
= 텍스트, 시각, 오디오 입력에 대한 다중모드 지원
= 입력 최대 100만 토큰, 출력 최대 6만4000 토큰
= 구글 TPU로 훈련, LLM 훈련 특화로 특별히 설계
= 2025년 1월까지의 정보를 바탕으로 학습
= '다중 턴 대화'에서 성능저하 가능성 있음
= 어조(tone) 면에서 2.5 프로보다 우수
구글 딥마인드, 차세대 AI ‘제미니 3 프로’ 공개: 100만 토큰 컨텍스트와 강력한 에이전트 기능 탑재
구글 딥마인드가 2025년 11월, 제미니 시리즈의 최신작 ‘제미니 3 프로(Gemini 3 Pro)’의 모델 카드를 공개했습니다. 이번 모델은 텍스트, 이미지, 오디오, 영상, 코드를 모두 처리하는 네이티브 멀티모달 구조와 대규모 추론 능력을 바탕으로, 기존 ‘제미니 2.5 프로’를 완전히 대체하는 차세대 플래그십 모델로 평가받습니다.
---
차세대 아키텍처: 스파스 MoE 기반 멀티모달 트랜스포머
제미니 3 프로는 기존 모델을 파인튜닝한 것이 아니라, 처음부터 새롭게 설계된 ‘스파스 Mixture-of-Experts(MoE)’ 아키텍처를 기반으로 합니다. 이 모델은 텍스트, 이미지, 오디오, 영상, 코드 리포지토리 전체를 입력으로 처리하며, 최대 100만 토큰에 달하는 방대한 컨텍스트 창(Context Window)을 지원합니다. 출력은 최대 6만 4천 토큰까지 생성할 수 있습니다.
스파스 MoE 구조는 각 토큰을 처리할 때 일부 ‘전문가(Expert)’ 파라미터만 활성화하여, 모델의 총용량과 실제 추론 비용을 분리합니다. 덕분에 “모델의 전체 용량은 키우면서도, 토큰당 계산 비용은 억제”하는 효율적인 접근이 가능해졌습니다. 이는 긴 맥락을 처리하거나 여러 단계의 복잡한 추론을 수행할 때 특히 유리한 설계입니다.
---
학습 데이터: 웹, 코드, 멀티모달, 사용자, 합성 데이터 총망라
모델 카드에 따르면, 제미니 3 프로는 방대한 데이터셋으로 사전 학습되었습니다. 이 데이터셋에는 대규모 웹 문서, 다양한 프로그래밍 언어 코드, 이미지·오디오·비디오 등 멀티모달 데이터가 총망라되었습니다.
사전 학습 이후에는 멀티모달 지시-응답 데이터, 인간 선호도 데이터, 도구 사용 예시 등을 활용한 미세조정(Fine-tuning)을 거쳤습니다. 특히 다단계 추론, 문제 해결, 정리/증명 등 고차원적 능력을 강화하기 위한 강화학습도 병행되었습니다.
데이터 출처는 다음과 같습니다.
* 공개 웹 및 공개 데이터셋
* 상업적 라이선스로 확보한 데이터
* 구글 서비스 이용자 데이터 (약관, 개인정보처리방침, 사용자 제어 설정 준수)
* 구글 내부 업무 및 워크포스 생성 데이터
* AI가 생성한 합성 데이터
수집된 데이터는 중복 제거, robots.txt 준수, 유해 콘텐츠(음란물, 폭력, 아동 성 착취물 등) 필터링, 품질 필터링 등 다단계 전처리 과정을 거쳐 학습에 활용되었습니다.
---
TPU 기반의 대규모 학습과 지속 가능성
제미니 3 프로는 구글의 전용 하드웨어인 TPU(Tensor Processing Unit) 팟에서 JAX와 Pathways 스택을 활용해 학습되었습니다. TPU는 고대역폭 메모리와 대규모 분산 학습에 최적화되어, 대형 모델의 학습 속도와 효율을 극대화하는 핵심 역할을 했습니다. 구글은 TPU의 높은 전력 효율이 대규모 모델 학습에 필요한 에너지와 탄소 배출량을 줄이는 데 기여한다며, 자사의 지속 가능성 전략과도 맞닿아 있음을 강조했습니다.
---
배포 채널: 앱부터 클라우드까지 구글 제품군에 전면 탑재
제미니 3 프로는 다음 채널을 통해 제공됩니다.
* Gemini 앱
* Google Cloud Vertex AI
* Google AI Studio 및 Gemini API
* Google AI Mode
* Google Antigravity
개발자와 기업은 API를 통해 모델에 접근할 수 있으며, 각 채널별 추가 약관(예: Gemini API 추가 약관, Google Cloud 서비스 약관)의 적용을 받습니다.
---
벤치마크 성능: 고난도 수학·코딩·에이전트 작업에서 2.5 프로 압도
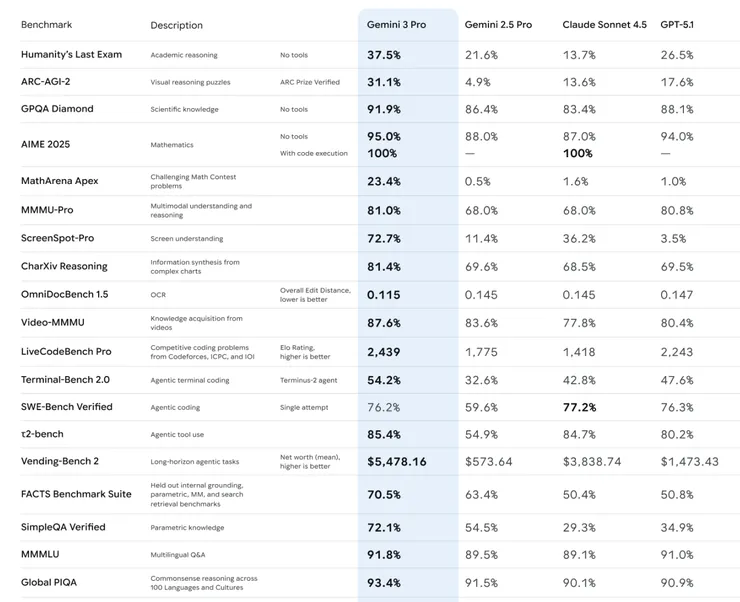
모델 카드는 제미니 3 프로가 2.5 프로 대비 다양한 벤치마크에서 의미 있는 성능 향상을 이뤄냈다고 밝힙니다. 대표적인 결과는 다음과 같습니다.
* Humanity’s Last Exam (학술 추론, 도구 없음): 37.5%로 2.5 프로(21.6%) 대비 큰 폭 상승
* ARC-AGI-2 (고난도 추론 퍼즐): 31.1%로 2.5 프로(4.9%)와 압도적인 격차
* GPOA Diamond (과학 지식): 91.9%로 2.5 프로(86.4%) 상회
* AIME 2025 (수학 경시, 도구 없음): 정답률 25.0%, 코드 실행 허용 시 100% 도달
* MATHarena Apex, MMMU-Pro, Video-MMMU 등 수학, 학문, 비디오 이해 벤치마크에서도 전반적으로 2.5 프로보다 높은 점수 기록
또한 LiveCodeBench Pro, SWE-Bench Verified 등 에이전트의 코드 작성, 도구 사용, 테스트 통과 능력을 평가하는 벤치마크에서도 제미니 3 프로는 2.5 프로는 물론 타사 모델(Claude Sonnet 4.5, GPT-5.1)과 비교해도 경쟁력 있는 수치를 기록했습니다.
종합적으로 제미니 3 프로는 ▲에이전트 기반의 도구 사용 ▲장문 컨텍스트 추론 ▲수학·코딩·멀티모달 이해라는 세 가지 핵심 영역에서 전 세대 모델을 압도하는 성능을 보여줍니다. 이는 복잡한 실제 업무 해결을 목표로 개발되었음을 명확히 보여주는 대목입니다.
---
활용 분야: 복잡한 현실 문제를 단계적으로 해결하는 에이전트
구글은 제미니 3 프로를 “가장 지능적이고 적응력이 뛰어난 모델”로 정의하며, 다음과 같은 활용 시나리오를 제시합니다.
* 에이전트형 작업: 도구 호출, 다단계 계획 수립, 워크플로 자동화
* 고급 코딩: 코드 리포지토리 단위의 이해, 변환, 리팩토링
* 장문 분석: 100만 토큰 분량의 문서, 코드, 로그 분석
* 멀티모달 분석: 텍스트, 이미지, 오디오, 비디오를 동시에 활용한 종합 분석
* 이론 문제 해결: 알고리즘 설계 및 이론적 문제 해결
다만, 모델의 지식은 2025년 1월까지의 정보로 제한되어 있어, 그 이후의 최신 사건이나 정보에 대해서는 답변하지 못하는 한계가 있습니다.
---
한계와 위험: 환각, 응답 지연, 멀티턴 대화 품질 저하 가능성
모델 카드는 제미니 3 프로 역시 기존 거대 언어 모델의 고질적인 한계를 지니고 있음을 명시합니다. 허위 정보(‘환각’)를 생성할 수 있으며, 응답 지연이나 타임아웃이 발생할 수 있습니다.
또한, 모델 카드에서는 다음과 같은 주요 잔여 위험(Residual Risks)을 명시했습니다.
* 프롬프트 공격 및 탈옥(Jailbreak) 취약성: 2.5 프로보다 개선되었으나 여전히 연구 과제로 남아있음
* 멀티턴(Multi-turn) 대화 품질 저하: 대화가 길어질수록 품질이나 안정성이 떨어질 수 있음
---
안전과 윤리: 다층적 평가와 ‘불필요한 거절 줄이기’
제미니 3 프로는 개발 과정 전반에 걸쳐 엄격한 안전성 평가를 거쳤습니다.
* 훈련 중·후 반복적인 자동 및 인간 평가
* 모델 팀 외부 전문팀에 의한 인간 레드팀(Red Team) 수행
* 대규모 자동 레드팀 수행
* 윤리 및 안전 정책 리뷰
* Google DeepMind의 프런티어 안전 프레임워크(Frontier Safety Framework) 기반 테스트
안전 정책은 특히 다음 6가지 유해 콘텐츠 생성을 차단하는 데 중점을 둡니다.
1. 아동 성 착취 및 학대
2. 증오 발언
3. 자해, 폭력, 범죄 등 위험한 콘텐츠
4. 괴롭힘
5. 노골적인 성적 콘텐츠
6. 과학적·의학적 합의에 반하는 의료 조언
내부 자동 평가 결과, 제미니 2.5 프로와 비교했을 때 흥미로운 지점이 발견됩니다. 텍스트 생성의 전반적인 안전성 점수는 소폭 하락(-10.4%)했지만, 다국어(+0.2%) 및 이미지 기반(+3.1%) 안전성은 향상되었습니다. 특히, 부당하게 답변을 거절하는 경우는 줄이면서(+3.7%) 거절 시의 어조는 개선(+7.9%)하는 등, ‘불필요한 거절을 줄이면서도 핵심 안전성은 유지’하려는 노력이 엿보입니다.
전문 레드팀 평가 결과, 아동 안전과 전반적인 콘텐츠 안전 기준에서 2.5 프로와 “동일하거나 개선된” 수준을 보였으며, 심각한 우려 사항은 발견되지 않았다고 밝혔습니다.
---
프런티어 안전 평가: “임계 능력 수준에 도달하지 않았다”
모델 카드 마지막에는 프런티어 안전 프레임워크에 따른 ‘임계 능력 수준(Capability Critical Level, CCL)’ 평가 결과가 요약되어 있습니다.
* CBRN (화학·생물·방사능·핵): 위협 행위자에게 유의미한 수준의 새로운 지침을 제공하지 못해 CCL 미달
* 사이버보안: v1 난이도 문제 11/12 해결, v2 문제는 0/13 해결. 경보 기준에 미치지 못해 CCL 미달
* 유해한 조작 (Harmful Manipulation): 비-AI 기준선 대비 조작 능력은 향상되었으나, 이전 모델 대비 추가 상승 폭이 크지 않아 CCL 미달
* 기계학습 R&D 가속: 특정 연구 벤치마크에서 2.5 계열을 앞섰지만, 총점은 여전히 CCL 경보 기준 이하
* 비정렬성 (오용·은닉 행동) 탐지: 제한된 상황에서만 은닉 행동에 성공하여 CCL 미달
결론적으로 제미니 3 프로는 강력한 범용 능력을 갖추었지만, 구글의 내부 프레임워크 기준상 ‘인류에게 심각한 위협을 초래할 수 있는 특수 능력(프런티어 위험)’에는 아직 도달하지 않았다는 것이 공식적인 평가입니다.
---
종합 분석: ‘실전형 멀티모달 에이전트’를 지향하는 플래그십
모델 카드의 내용을 종합하면, 제미니 3 프로의 특징은 다음 세 가지로 요약할 수 있습니다.
1. 실무 환경을 겨냥한 ‘에이전트’로서의 정체성 강화
100만 토큰 컨텍스트, 코드 리포지토리 단위의 이해, 각종 에이전트 및 코딩 벤치마크에서의 성능 개선은 단순 질의응답을 넘어, 복잡한 프로젝트를 단계별로 해결하는 ‘실전형 모델’을 지향함을 보여줍니다.
2. 구글 생태계와의 완벽한 통합을 위한 ‘상용 모델’
웹, 코드, 합성, 사용자 데이터를 아우르는 학습 파이프라인과 다층적 안전 필터 및 정책 체계를 결합하여, Gemini 앱, 클라우드, API 등 구글 생태계 전반에 즉시 탑재할 수 있는 ‘상용 서비스용 베이스 모델’로 설계되었습니다.
3. 통제된 위험 속 ‘점진적 성능 향상’ 전략
프런티어 안전 프레임워크 평가에서 CCL을 넘지 않는 선에서 고난도 수학, 코딩, 추론 성능을 끌어올린 점은, ‘위험한 능력의 급격한 도약 없이 범용 지능을 점진적으로 상향’하려는 구글의 전략을 엿보게 합니다.
결론적으로 제미니 3 프로는 제미니 2.5 프로를 대체하는 구글의 차세대 주력 LLM입니다. 긴 맥락 처리, 에이전트, 코딩, 멀티모달 작업에 특화된 상용 모델로서, 실제 제품과 업무 자동화에 곧바로 투입될 준비를 마쳤음을 보여주고 있습니다.
