안녕하십니까!! 심심해잉 입니다.
번역기로 인한 오역이 있을 수 있습니다.
Intel 4세대 Xeon Scalable Sapphire Rapids 성능및 벤치마크
Intel 4세대 Xeon 확장 가능: 다양한 데이터 센터 워크로드에서 테스트된 Sapphire Rapids


인텔 은 화요일 코드네임 사파이어 래피즈(Sapphire Rapids)라는 4세대 제온 스케일러블 CPU 를 공식 출시했습니다 . 이러한 혁신적인 데이터 센터 프로세서는 AMD의 4세대 EPYC "Genoa" CPU와 대결하게 될 것입니다. AMD EPYC 서버 프로세서는 최근 Intel의 시장 점유율을 끌어모았고, 이 라운드는 열풍에 이르렀습니다. 오늘날 우리는 이러한 플랫폼을 직접 비교하여 각각의 강점과 약점이 어디에 있는지 확인하고 있습니다.
제노아 출시 당시 논의한 바와 같이, 이 두 칩 거물은 서로 다른 전략을 채택하여 비교가 다소 모호합니다. AMD는 광범위한 고객과 애플리케이션을 만족시키기 위해 최대의 일반 컴퓨팅 성능을 제공하는 데 주력해 왔습니다. EPYC Genoa 프로세서는 소켓당 최대 96개의 CPU 코어를 공급할 수 있으며 12채널 DDR5 메모리 및 PCIe Gen 5 인터페이스를 구부려 다른 몇 가지 사양 시트 토핑 기능을 지정합니다. 그 대가로 마이크로아키텍처는 AVX-512와 같은 특수 명령어에 대한 지원을 가져왔지만 "특수" 실리콘 방식을 상대적으로 거의 제공하지 않습니다.

Intel Xeon Platinum 8480+(왼쪽) 및 AMD EPYC 9554(오른쪽)
대조적으로 Intel의 4세대 Sapphire Rapids Xeon CPU는 상대적으로 축소된 것처럼 들립니다. 이 프로세서는 소켓당 60개의 CPU 코어를 자랑합니다. 이러한 칩은 DDR5 메모리 와 PCIe Gen 5도 지원하지만 DDR5 지원은 8채널로 제한됩니다. 이것의 영향은 더 낮은 피크 메모리 대역폭이지만 8개 채널이 여전히 대부분의 워크로드에 대해 건강한 양을 제공한다고 말해야 합니다.
인텔은 대신 워크로드 가속기의 형태로 약간의 특별한 소스를 가져오고 있습니다.. 인텔은 특수 제작된 실리콘 배열을 포함함으로써 특정 작업을 더 빠르고 전력 효율적으로 완료할 수 있을 뿐만 아니라 나머지 범용 작업을 처리하기 위해 CPU 코어를 확보할 수 있다고 생각합니다. 이 세대는 Intel의 설계 전략에서 일종의 변곡점을 표시하며 베팅이 성공하면 가속기 라인업이 확장되는 것을 기대할 수 있습니다.

Intel의 듀얼 소켓 Xeon 테스트 플랫폼
사내 테스트를 위해 Intel은 3개의 칩 세트와 함께 2U 참조 서버 플랫폼을 통해 보냈습니다. 여기에는 작년 10월 가속기 워크로드 프리뷰 에서 사용된 한 쌍의 프로세서가 포함되며 , 각각 전체 60코어의 Xeon Platinum 8490H로 밝혀졌습니다. 또한 56코어 Xeon Platinum 8480+ 칩 한 쌍과 32코어 Xeon Platinum 8462Y+ 한 쌍이 있어 전반적으로 코어와 스레드의 양은 정상입니다.
Intel 4세대 Xeon Scalable 프로세서: 제품군.
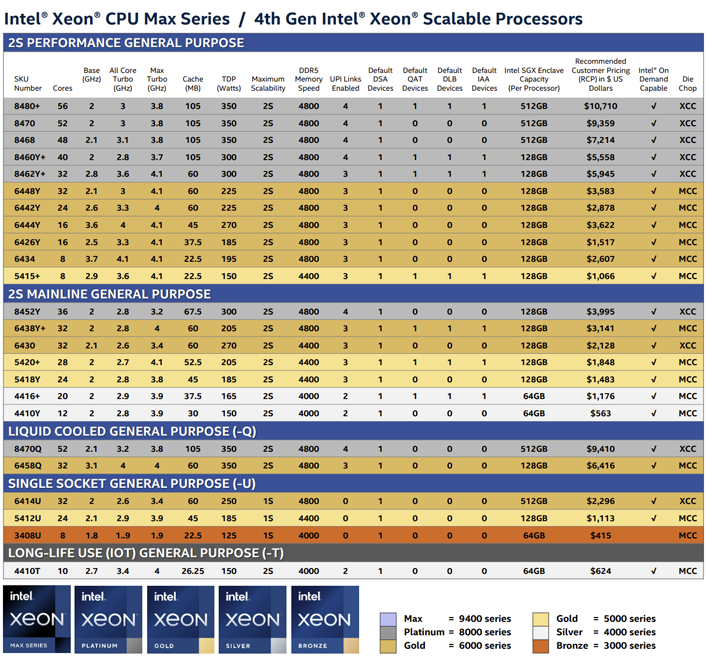
이러한 모든 프로세서는 코어 수뿐만 아니라 클럭 주파수, 캐시 및 가속기 수에 따라 다릅니다. 마지막 측면에서 8480+와 8462Y+가 가장 유사합니다. 이러한 SKU의 더하기(+)는 각 유형의 단일 액셀러레이터가 활성화된 상태로 도착함을 나타냅니다. 8462Y+는 총 캐시가 60MB에서 8480+의 105MB보다 적지만 코어당 총 캐시는 동일합니다. 8462Y+는 더 높은 기본 클럭(2.8GHz vs 2.0GHz)과 더 높은 터보 클럭(4.1GHz vs 3.8GHz)으로 인해 더 높은 클럭을 밀어냅니다. 둘 다 인텔에서 "2S 성능 범용" 프로세서로 분류합니다.
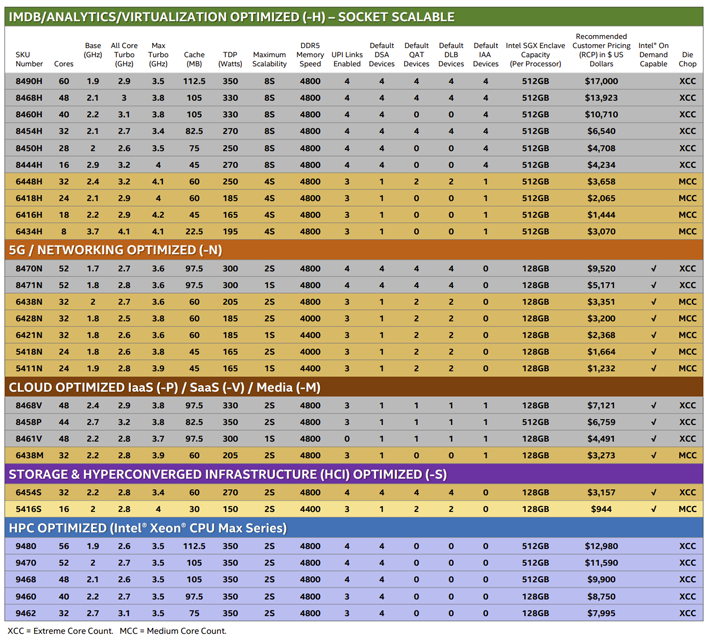
반대로 60코어 8490H는 더 많은 기능을 제공합니다. 각 가속기 4개(타일당 1개)와 함께 완전히 활성화되어 배송되며 총 캐시를 112.5MB로 확장하여 코어당 캐시 비율을 동일하게 유지합니다. 또한 다른 2개의 SKU가 2소켓 설정으로 제한되는 최대 8소켓 시스템까지 확장할 수 있습니다. 전력의 트레이드 오프는 1.9GHz의 기본 클럭과 최대 3.5GHz의 최대 터보 클럭 속도로 더 낮은 클럭 속도입니다. 또한 데이터 센터 칩의 실제 가격은 이러한 경쟁업체가 디자인 승리를 위해 경쟁할 때 권장 소비자 가격이 증명할 수 있는 것보다 항상 약간 모호하지만 라인업에서 가장 비싼 가격을 팝당 17,000달러로 유지합니다.
여기서 얻을 수 있는 실질적인 이점은 Intel의 4세대 Xeon 라인업이 다양한 유형의 워크로드를 위한 광범위한 기능과 기능으로 유연성을 제공한다는 것입니다. 잠재 구매자는 의도된 응용 프로그램과 특정 SKU의 성능을 신중하게 고려해야 합니다. 이는 여기에서 테스트할 수 없는 특수 네트워킹, 클라우드 및 스토리지/HCI 옵션의 경우 특히 그렇습니다.
Intel 4세대 Xeon Scalable Sapphire Rapids 벤치마크
Intel 4세대 Xeon Scalable CPU: 일반 컴퓨팅 워크로드
HotHardware의 서버 테스트 설정
Intel 4세대 Xeon 및 AMD EPYC 시스템 모두 Ubuntu Server를 실행하고 있습니다. 거버너가 성능으로 설정된 상태에서 Linux 커널을 5.15.0-57-generic으로 업데이트했습니다. 우리는 Phoronix Test Suite, 모든 대상 벤치마크를 설치한 다음 최종 적절한 업데이트/업그레이드 주기를 설치했습니다.
Genoa와 마찬가지로 Phoronix Test Suite를 사용하기로 선택한 이유는 선택할 수 있는 다양한 테스트와 재현 용이성을 모두 제공하기 때문입니다. 참고로 openbenchmarking.org 를 방문 하여 추가 정보, 참조 번호를 확인하고 원하는 경우 기존 인프라를 이러한 워크로드와 비교할 것을 권장합니다.
여기에 제시된 모든 제노아 번호는 이 검토를 위해 다시 실행되었습니다. 대부분의 테스트는 몇 가지 더 상당한 변화가 있었지만 실행 간 편차 내에 유지되었습니다. 우리는 그것들에 도달하는 대로 그것들을 다룰 것입니다.
코어마크 1.0.1 벤치마크
Coremark로 테스트를 시작합니다. Coremark는 빠른 비교를 위한 매우 빠른 멀티 스레드 CPU 테스트입니다.
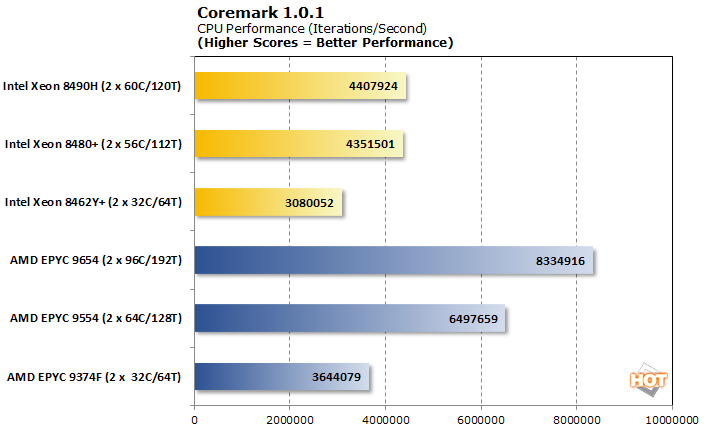
Coremark는 Xeon과 EPYC 플랫폼 간의 놀라운 차이점으로 시작합니다. 먼저, 각각 소켓당 32개의 코어가 있는 EPYC 9374F와 Xeon 8462Y+를 비교하는 유일한 진정한 코어 대 코어 비교를 살펴보겠습니다. EPYC 9374F는 약 200MHz의 최고 클록 속도 이점을 보유하지만 기본 클록은 Xeon 8462Y+의 2.8GHz 베이스에 비해 훨씬 더 높은 3.85GHz를 유지합니다. 이와 같은 모든 코어 부하를 사용하면 CPU 기본 클럭 이점이 훨씬 더 중요해집니다.
최고 수준에서 Intel의 Xeon 8480+ 및 8490H CPU는 여기서 AMD의 64코어 EPYC 9554와 경쟁하지 않으며 96코어 EPYC 9654는 말할 것도 없습니다. 다시 AMD는 둘 중 하나보다 1GHz 이상의 기본 클럭 리드를 보유하고 있습니다. 소켓당 더 많은 코어를 가진 이러한 Intel 경쟁자 중 하나입니다.
7-Zip 1.10.0 압축/압축 해제
다음으로 7-Zip 압축 및 압축 해제를 살펴보았습니다. 압축 워크로드는 메모리 및 캐시 성능과 비순차적 처리의 영향을 받습니다. 압축 해제는 훨씬 더 정수 기반이지만 분기 예측 파이프라인도 강조합니다.
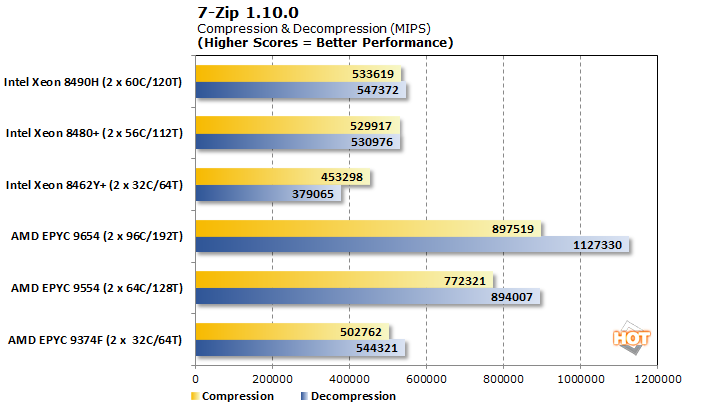
7-Zip 워크로드는 Coremark와 비슷한 순위를 보여주었지만 56코어 및 60코어 Intel Xeon 프로세서는 여기서 더 뒤떨어졌습니다. 압축 워크로드의 성능 델타는 크지만 압축 해제 하위 테스트의 성능 델타는 훨씬 더 큽니다. 이는 8채널 대 12채널의 메모리 대역폭 감소가 원인이 아님을 시사합니다.
Linux 커널 컴파일 1.15.0
소프트웨어 컴파일은 일반적인 작업이며 Linux 커널 자체를 빌드하는 것은 오랫동안 성능 벤치마크로 사용되었습니다. 우리는 defconfig 및 allmodconfig로 테스트했으며 결과는 몇 초 안에 보고되었습니다.
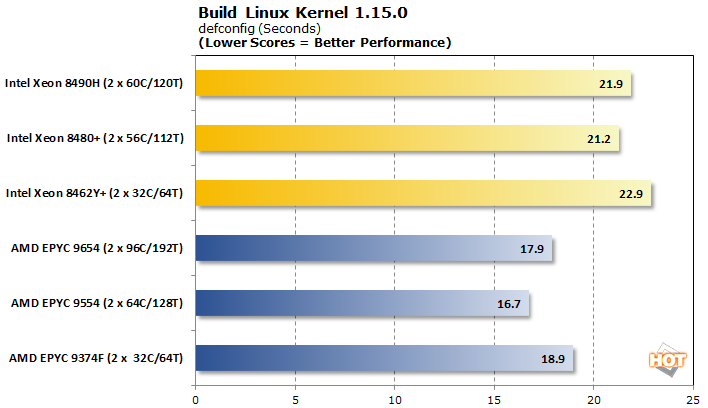
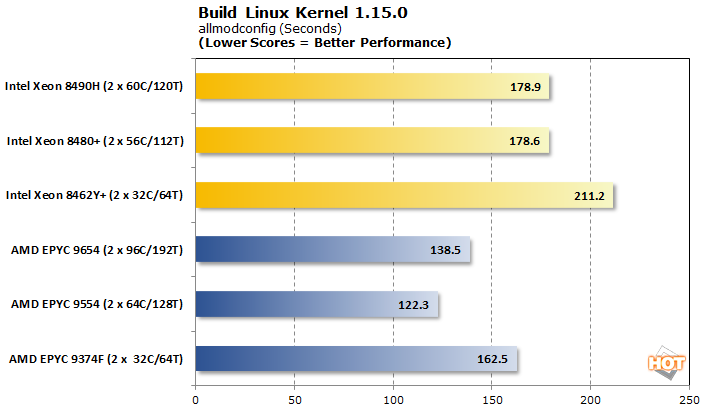
소프트웨어 컴파일과 관련하여 AMD EPYC은 깔끔한 스윕을 기록하지만 마진은 적습니다. 흥미롭게도 두 플랫폼 모두 각각의 미들 티어 칩으로 성능 스위트 스폿이 있는 것으로 보입니다.
다카포 벤치마크 1.0.1
DaCapo 벤치마크 제품군은 Java 컨텍스트에서 CPU 및 시스템 전체의 성능을 평가합니다. 특히 Java 환경에서 개발하려는 Python 개발자들 사이에서 인기를 얻고 있는 Jython 테스트를 사용하고 있습니다.
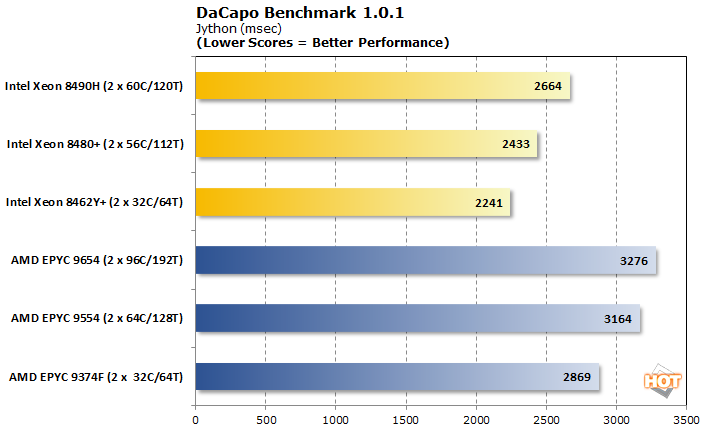
우리의 DaCapo 결과는 Linux Kernel 결과와 반대이며 인텔이 분명히 선두를 달리고 있습니다. 여기서는 낮을수록 좋습니다. 그러나 자세히 살펴보면 파란색 팀과 빨간색 팀 모두에 대한 추가 코어로 인해 성능이 약간 떨어지는 이상한 추세가 나타납니다. 이렇게 코어 수가 적은 부분은 단순한 무차별 대입 컴퓨팅에 비해 Java를 최고 속도로 실행하기 위해 더 나은 메모리와 코어 간 대기 시간을 갖는 경향이 있습니다.
블렌더 BMW 3.4.0 모델 3D 렌더링
Blender는 주요 3D 렌더링 벤치마크입니다. 검증된 실제 BMW 장면을 대기열에 추가하고 렌더링 시간을 몇 초 단위로 측정했습니다.
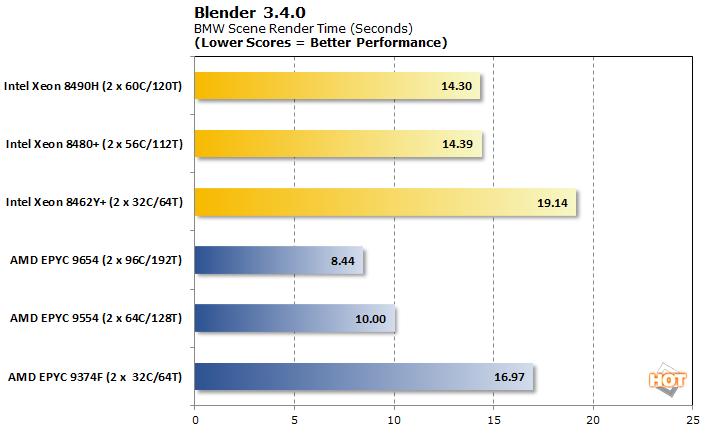
블렌더는 우리에게 AMD 이점을 제공합니다(말장난 의도 없음). 성능은 여기에서 코어 수에 따라 잘 확장되는 것으로 보이지만 코어 대 코어 Intel 프로세서는 AMD 프로세서를 뒤쫓습니다.
Embree 1.2.1 3D 렌더링
Embree는 AVX2 및 AVX512와 같은 명령어 세트를 활용할 수 있는 3D 경로 추적 렌더러입니다. IPSC 변형은 AVX 가속을 사용할 수 있을 때 추가 속도 향상을 볼 수 있는 인텔 암시적 SPMD 프로그램 컴파일러를 사용하여 컴파일됩니다.
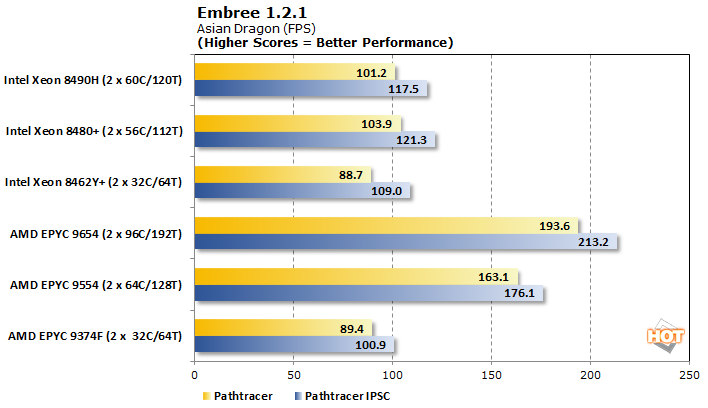
순위는 두 시나리오에서 비슷합니다. 가장 주목할만한 점은 Intel 칩의 코어당 스케일링이 부족하다는 것입니다. 가능한 범인은 Intel이 타일에서 AVX/AVX-512 가속기를 세분화한 것인데, 이는 모델 간에 거의 동일합니다. AMD의 AVX 구현은 코어 수준이므로 코어 수 확장의 이점이 있습니다. 이것은 또한 Xeon 8462Y+가 EPYC 9374F에 비해 손익분기점이 있거나 심지어 약간 앞서는 것도 설명할 수 있습니다. 이것은 EPYC 9554와 9654 모두 원래 테스트보다 약간의 성능을 얻은 워크로드입니다.
x264 2.7.0 비디오 인코딩
이러한 서버의 또 다른 일반적인 용도는 비디오용 렌더 팜 역할을 하는 것입니다. 우리는 1080p 및 4K 테스트 영상 모두에 멀티스레드 x264 인코더를 사용했습니다.
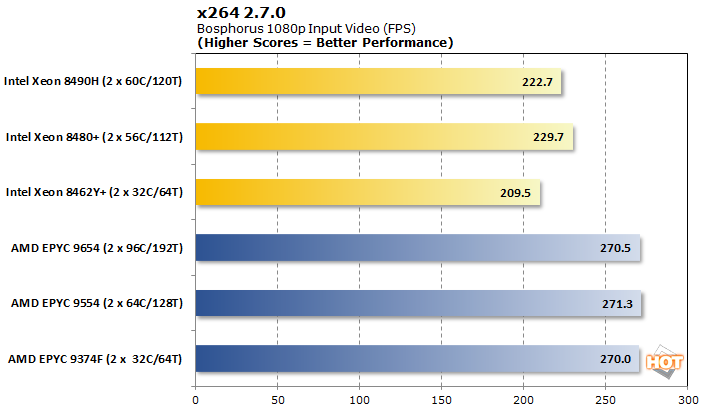
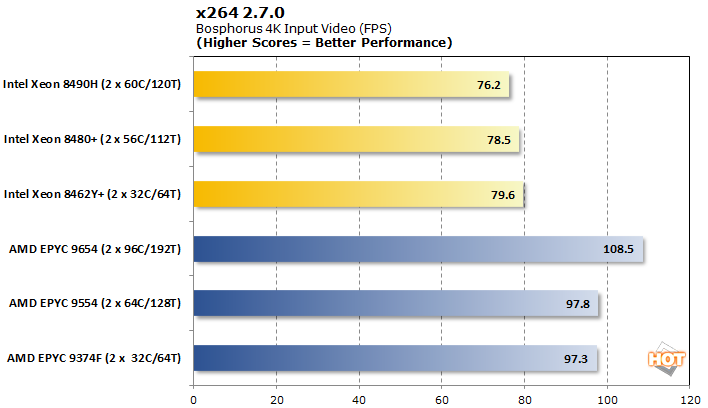
AMD는 1080p 및 4K 인코딩 경로 모두에서 상대적으로 좁은 이점을 유지합니다. 이번에는 적어도 고객이 스택 위로 이동하도록 강요하는 어떤 식으로든 두 진영에서 말할 실제 확장이 없습니다.
PostgreSQL PGBench 1.13.0 데이터베이스 트랜잭션 벤치마크
PostgreSQL은 매우 인기가 있으며 데이터베이스 처리 성능을 보여줍니다. PGBench는 읽기 전용 및 읽기-쓰기 워크로드를 모두 사용하여 초당 데이터베이스 트랜잭션 등급과 해당 평균 대기 시간을 제공합니다.
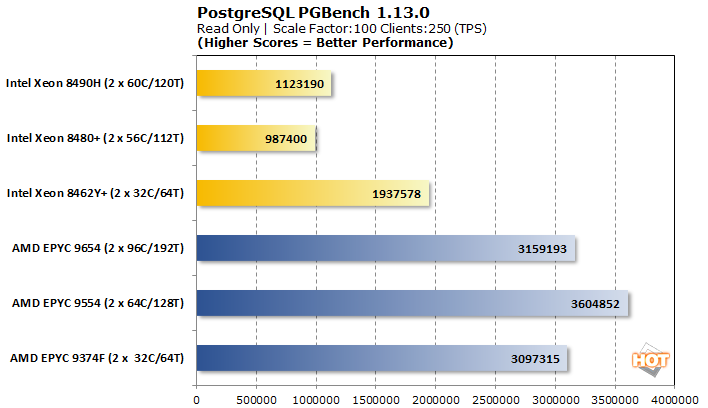
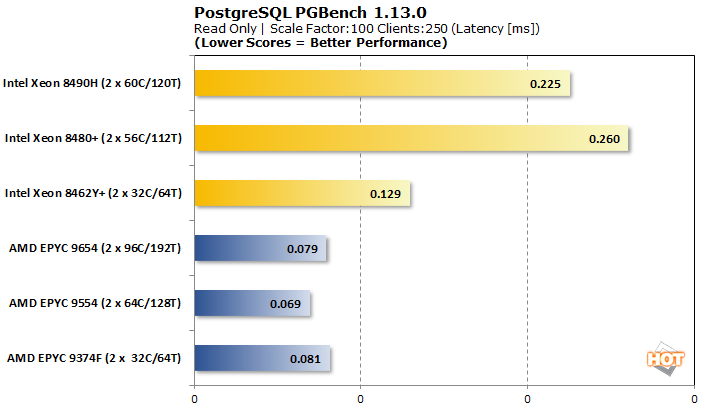
캠프 간의 성능 차이는 한마디로 극명합니다. 읽기 전용 워크로드에서는 Intel의 32코어 Xeon 8462Y+만이 모든 종류의 싸움을 합니다. 그럼에도 불구하고 AMD 칩의 초당 트랜잭션 수의 절반 이상만 처리합니다. 대기 시간도 거의 두 배가 되지만 Xeon 8480+ 및 8490H는 여기서 뒤처집니다.
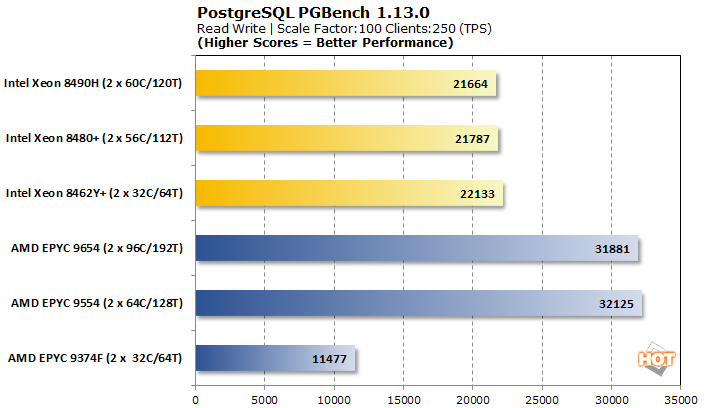
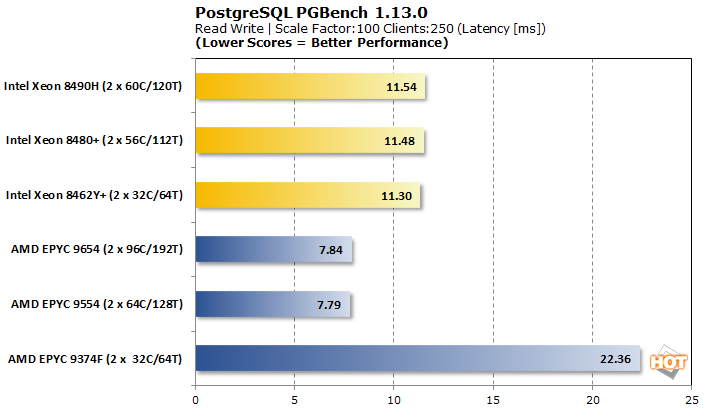
쓰기가 방정식에 입력되면 인텔이 더 잘 작동합니다. AMD의 상위 SKU는 여전히 약 45% 더 빠릅니다. 원래 AMD Genoa 리뷰 에서 보았 듯이 EPYC 9374F는 여기에서 보조를 맞추기 위해 고군분투하고 있으며 단순히 더 나은 옵션이 있기 때문에 일반적으로 PostgreSQL 워크로드에서는 피하는 것이 가장 좋습니다.
POV-Ray 1.2.1 레이 트레이싱 렌더링
POV-Ray 또는 Persistence of Vision Ray-Tracer는 사실적인 조명 이미지를 만들기 위한 오픈 소스 도구입니다. Phoronix Test Suite 구현은 일반적으로 다른 리뷰에서 보고하는 초당 픽셀 수보다 완료 시간을 측정합니다.
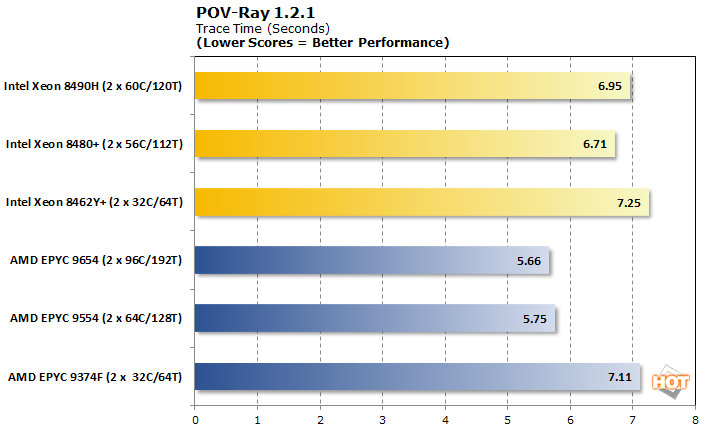
이러한 POV-Ray 결과는 다른 워크로드에서 관찰한 델타를 고려할 때 놀라울 정도로 경쟁력이 있습니다. 32코어 CPU는 막상막하이며, EPYC 9554는 Xeon 8490H 및 8480+보다 한 발 앞서 있지만, 그다지 많이도 아닙니다.
그러나 실제로 결론을 내리기 전에 잠재적으로 가속화된 몇 가지 워크로드를 더 검토하여 이러한 Xeon이 실제로 빛나는 곳을 확인하는 것이 공정합니다.
SMHasher 1.1.0 보안 처리 벤치마크
SMHasher는 다양한 해싱 알고리즘의 성능을 평가하는 벤치마크 도구입니다. 이러한 워크로드는 데이터 센터 전체에 나타나며 종종 보안 애플리케이션에 중요합니다. Wyhash는 완전히 안전한 것으로 간주되지는 않지만 매우 효율적이고 휴대 가능하며 빠릅니다.
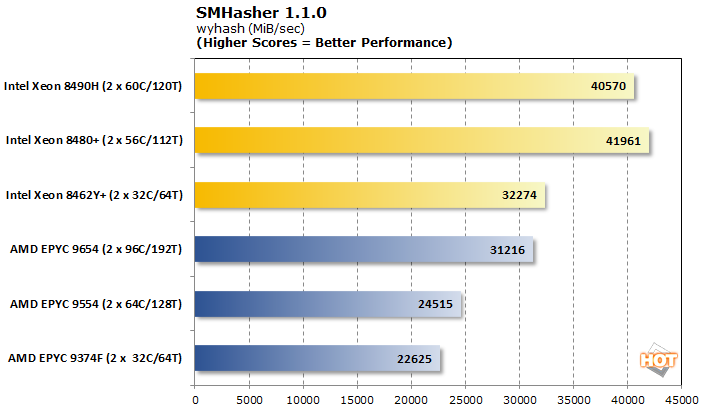
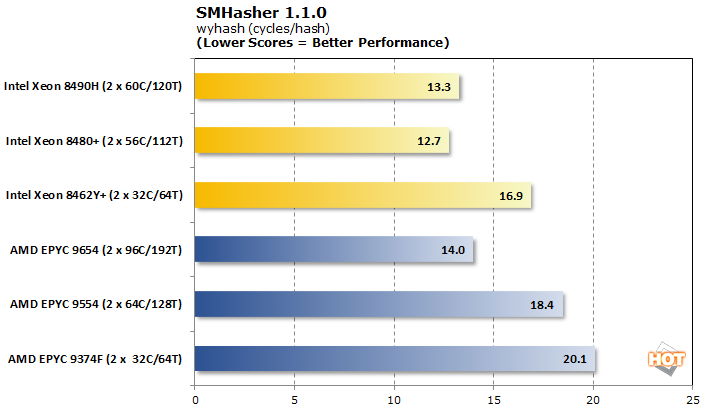
AVX가 본격화되면서 Intel 트리오는 몇 가지 인상적인 수치를 제시했습니다. 심지어 Xeon 8462Y+도 EPYC 9654보다 처리량이 3배나 많은 코어 수를 능가하지만 후자는 해시당 더 적은 주기를 소모합니다.
Intel Open Image Denoise 1.4.0 벤치마크
광선 추적의 중요한 측면은 보기 좋은 프레임을 위해 이미지를 정리하는 노이즈 제거 단계입니다. oneAPI의 일부인 Intel Open Image Denoise는 게임뿐만 아니라 애니메이션 기능에도 사용할 수 있는 라이브러리 중 하나입니다.
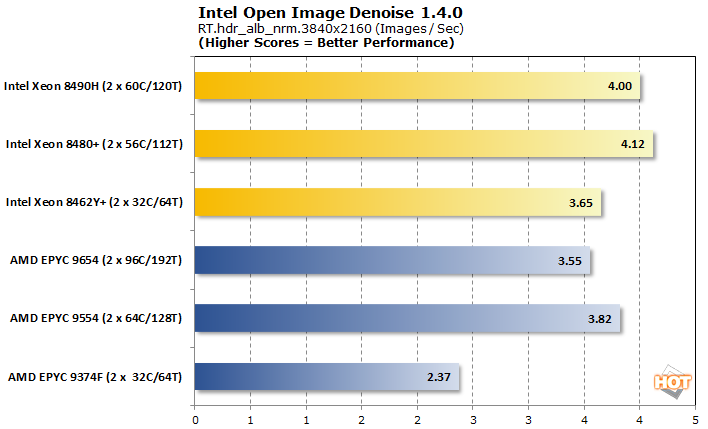
이것은 6개의 테스트 CPU 중 5개가 강력한 결과를 내는 또 다른 근접 비교입니다. 가속기를 사용하면 Intel Xeon 8462Y+ 도 팩과 보조를 맞출 수 있고 EPYC 9374F는 상당히 떨어질 수 있기 때문에 저울은 Intel에 다소 유리합니다.
TensorFlow 2.0.0 기계 학습 이미지 분류 벤치마크
TensorFlow는 분석할 수 있는 몇 가지 다른 모델을 제공하므로 사전 훈련된 신경망 이미지 분류 워크로드에 대해 VGG-16, AlexNet, GoogLeNet 및 ResNet-50을 테스트했습니다.
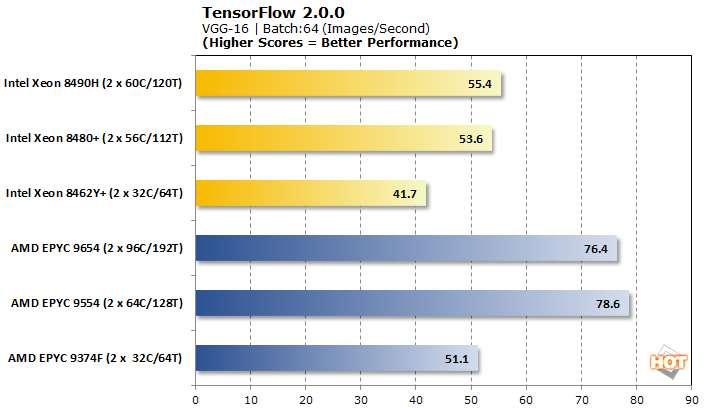
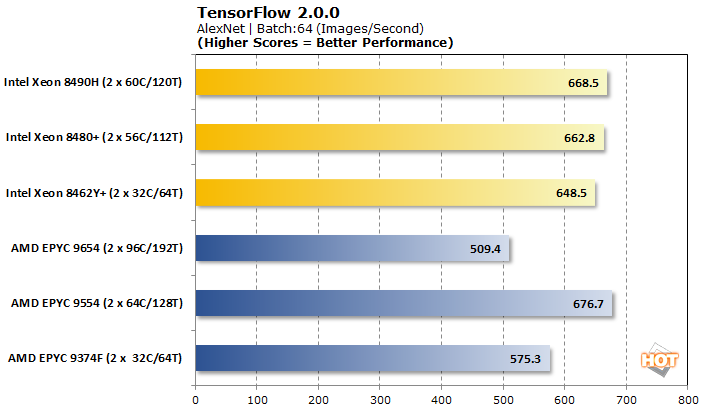
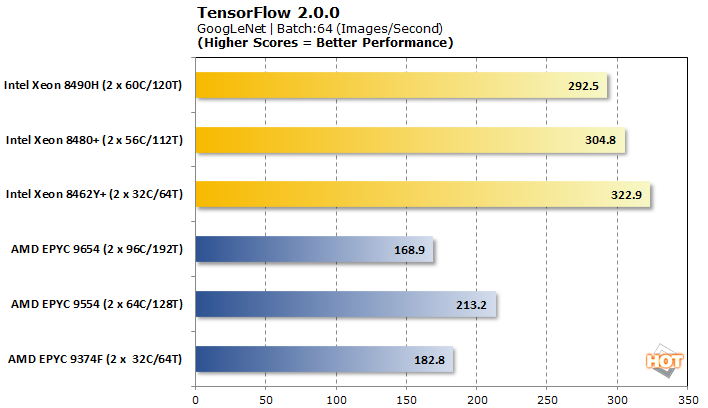
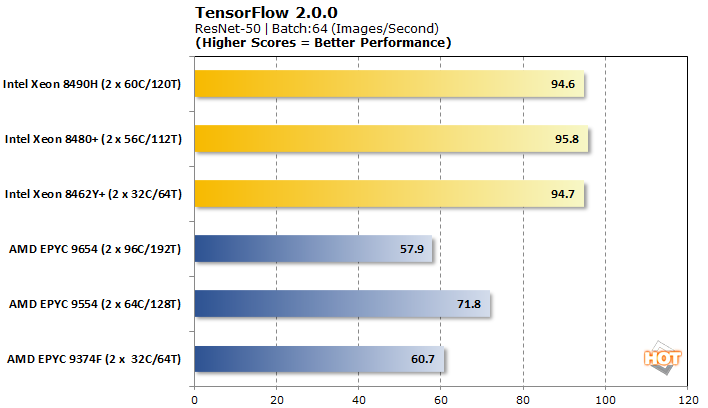
Tensorflow는 AMD EPYC Genoa 프로세서가 출시 이후 일반적으로 기반을 잡은 또 다른 벤치마크 입니다. 그럼에도 불구하고 Intel은 4개의 워크로드 중 3개에서 꽤 결정적인 승리를 거두었습니다. 일부 AMD 프로세서에서는 VGG-16만 더 잘 제공됩니다. 브랜드 내에서 성능 확장은 인텔에 거의 존재하지 않는 것부터 AMD에 완전히 불규칙한 것까지 모든 곳에서 조금씩 이루어집니다.
DeepSparse AI 추론 1.0.1 벤치마크
Neural Magic의 DeepSparse는 CPU용으로 특별히 개발 되었다는 점에서 많은 AI 추론 접근 방식과 다릅니다. 이름에서 알 수 있듯이 모델은 고도의 정확도를 유지하면서 CPU에서 "GPU급" 딥 러닝을 제공하기 위해 광범위하게 가지치기(예: 스파스화)됩니다.
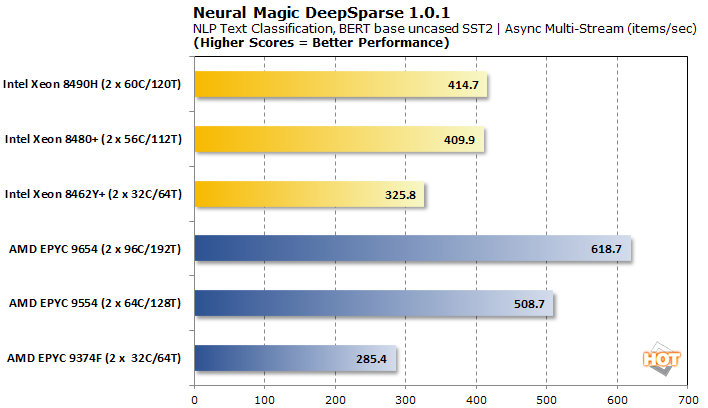
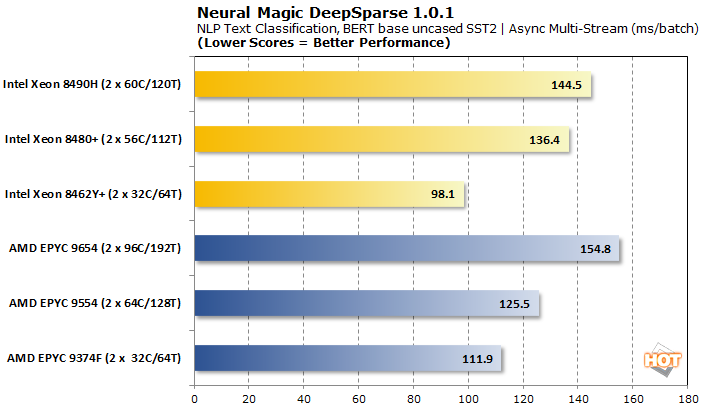
비동기식 멀티 스트림 배칭을 통해 Intel Xeons는 AMD EPYC에 비해 경쟁력 있는 배치당 대기 시간을 유지합니다. 결과 처리량은 32코어 부품을 제외하고 상당히 낮습니다.
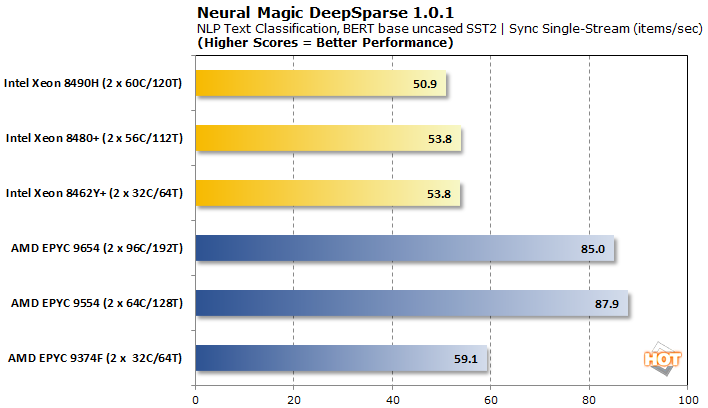
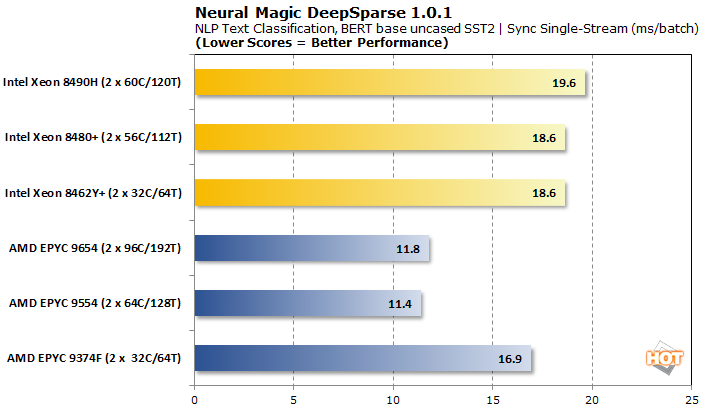
동기식 스트림으로 이동하면서 AMD EPYC CPU는 더 낮은 대기 시간으로 견고하게 앞장서고 있습니다. EPYC 9374F는 두 가지 측면에서 약간 뒤떨어져 있지만 여전히 모든 Xeon 경쟁자를 능가합니다.
OneDNN 3.0.0 RNN 교육 및 추론 벤치마크
OneDNN은 현재 oneAPI의 일부인 Intel에 최적화된 오픈 소스 신경망 라이브러리입니다. 우리의 테스트는 f32, u8u8f32 및 bf16bf16bf16의 세 가지 데이터 유형에서 컨볼루션, RNN 교육 및 RNN 추론의 성능을 살펴봅니다.
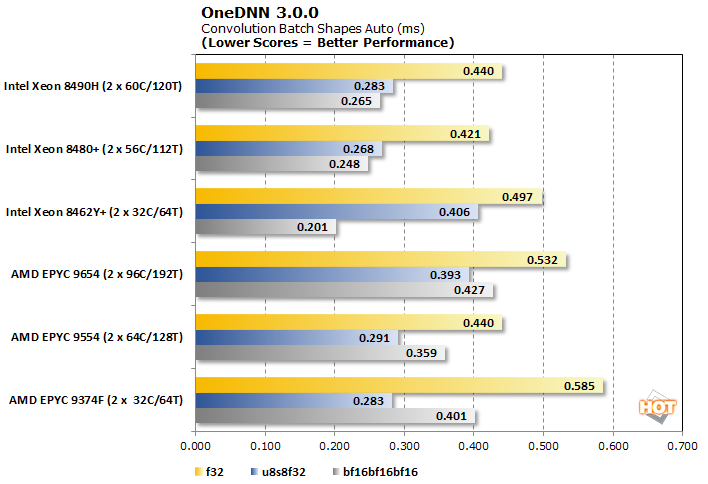
이러한 결과 는 f32가 있는 Intel Xeon CPU 의 약간의 이점 에서 bfloat16의 압도적인 승리에 이르기까지 다양합니다. 흥미롭게도 u8(서명되지 않은 8비트) 워크로드는 코어 수가 더 많은 Intel SKU를 선호하지만 대신 AMD의 Genoa 제품군의 코어 수가 더 적은 칩을 선호합니다.
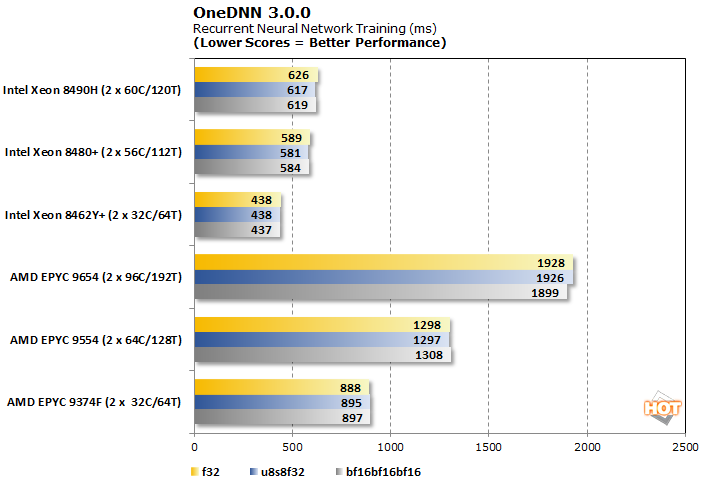
반복되는 신경망 교육 워크로드는 모든 SKU에 대해 가상 데이터 유형에 구애받지 않습니다. 더 나은 대기 시간을 달성하기 위해 코어 수가 적은 시스템에 대한 선호도를 관찰할 수 있지만 이 시나리오에서는 전반적으로 Intel Xeon이 훨씬 더 빠릅니다.
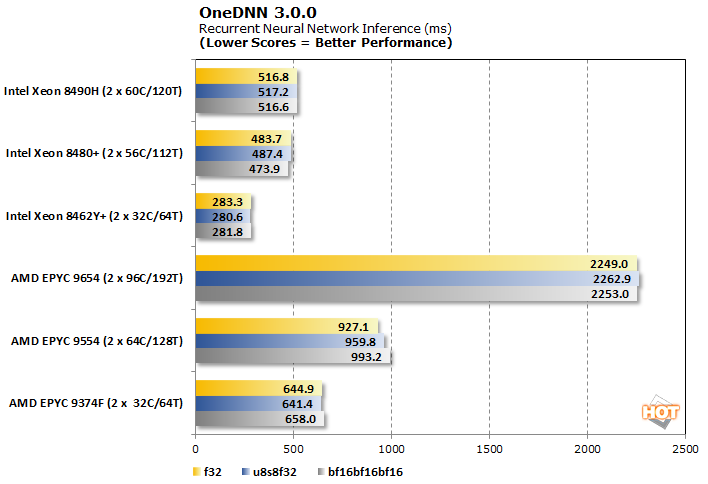
추론 구성 요소는 또한 Intel의 압도적인 승리를 보여주며, AMD EPYC 9654는 96코어의 무차별 대입 능력에도 불구하고 특히 여기에서 뒤처집니다.
Intel 4세대 Xeon 확장 가능 최종 생각 및 결론
Intel의 4세대 Xeon Scalable 프로세서를 평가하는 것은 확실히 까다로운 작업입니다. 기존 워크로드의 경우 AMD의 EPYC 프로세서 를 이기기가 매우 어려운 것으로 입증되었습니다 . 방정식에서 96코어 EPYC 9654를 제거하더라도 AMD는 파운드당 파운드(코어 대 코어) 기준으로 더 많은 것을 제공하는 것으로 보입니다.
그러나 범용 컴퓨팅은 최신 데이터 센터의 전체 스토리와는 거리가 멉니다. 개발자들은 빅 데이터 분석 문제를 해결하고 새로운 솔루션을 발견하기 위해 신경망 애플리케이션을 점점 더 많이 활용하고 있습니다. 이 작업의 대부분은 GPU 및 전용 가속기(예: FPGA)에서 수행되지만 인텔은 CPU가 잠재적으로 더 낮은 비용과 전체 설치 공간으로도 작업을 수행할 수 있음을 입증하고 있습니다. 결과적으로 작업에 적합한 도구에 도달하는 것과 같이 가속기를 활용할 수 있는 이러한 4세대 Xeon 프로세서 중 하나를 선택하는 것이 합리적일 수 있습니다.

여기서의 테스트는 혼합 워크로드 시나리오도 완전히 탐색하지 않습니다. 개별 가속기의 주요 이점은 CPU 코어가 다른 작업을 위해 효과적으로 확보된다는 것입니다. 결과적으로 실제 응용 프로그램은 훨씬 더 큰 효과를 위해 서로 다른 동시 작업으로 동시에(전력 및 열 허용) 둘 다 활용할 수 있어야 합니다.
인텔의 4세대 Xeon 제품군의 온보드 가속기와 범용 컴퓨팅 워크로드를 동시에 활용하는 조합 워크로드를 통해 나중에 이 평가로 돌아가기를 희망합니다.
그럼에도 불구하고 공식은 Intel의 "더 많은 코어 = 더 좋음"보다 더 복잡합니다. 가속기의 개별 특성은 해당 가속기의 기능을 쇼핑하는 고객이 CPU 사양 시트의 나머지 부분을 무시할 수 있음을 알 수 있음을 의미할 수 있습니다. 코어 수가 적은 Xeon은 대기 시간이 짧고 코어당 클럭 속도가 더 좋아 예를 들어 AI 유형 워크로드에서 우위를 점할 수 있습니다.

방안의 다른 코끼리는 인텔의 "주문형" 서비스 모델입니다. "완전히 활성화된" -H 시리즈 및 HBM이 장착된 Xeon Max 제품 외에도 가속기(또는 그 이상)를 활성화하려는 고객은 라이선스에 대한 추가 청구서에 직면할 수 있습니다. 물론 이것은 다른 고객에게 더 낮은 진입 비용을 제공할 수 있지만 어쨌든 동일한 고객이 AMD 진영에 더 적합할 수 있습니다. 또한 가속기가 실리콘에서 완전히 작동한다는 사실을 변경하지 않으며 비용 없이는 사용할 수 없습니다.
인텔의 가속기가 AI 유형 워크로드에만 국한되지 않는다는 점도 지적하고 싶습니다. 인텔은 네트워킹, 동적 로드 밸런싱, 데이터 스트리밍, 인메모리 분석 등을 위한 가속기를 보유하고 있습니다. 우리가 본 것을 바탕으로 우리는 앞으로 더 다양한 용도로 제작된 실리콘을 볼 수 있을 것이라고 절대적으로 기대할 수 있다고 생각합니다. 인텔의 타일형 칩렛 접근 방식은 개별 고객 요구에 대한 진정한 맞춤형 레시피의 문을 열 수도 있습니다.