Gemma 4 12B를 소개합니다: 인코더가 필요 없는 통합 멀티모달 모델 (크롬 브라우저 번역)
Gemma 4 12B는 고성능 멀티모달 인텔리전스를 노트북에 직접 제공하도록 설계되었으며, 모바일 우선 효율성과 고급 추론 기능을 결합합니다.
오늘, 저희는 노트북에 에이전트형 멀티모달 인텔리전스를 직접 구현하도록 설계된 최신 모델인 Gemma 4 12B를 소개합니다. 엣지 컴퓨팅에 최적화된 E4B와 더욱 발전된 MoE(Mixture of Experts) 26B 사이의 간극을 메우는 Gemma 4 12B는 더 작은 메모리 용량 안에 강력한 기능을 담았습니다. 또한, 네이티브 오디오 입력을 지원하는 최초의 미드사이즈 모델이기도 합니다.
개발자 커뮤니티 덕분에 Gemma 4 모델 다운로드 수가 1억 5천만 건을 돌파했습니다. 여러분은 신체 보조 용 웨어러블 로봇 팔 부터 기업 수준의 AI 보안 솔루션 까지 다양한 제품을 개발해 오셨습니다 . 이번 최신 기능을 활용하여 여러분이 어떤 멋진 제품을 만들어낼지 기대됩니다.
Gemma 4 12B를 특별하게 만드는 요소들을 간략하게 살펴보겠습니다.
- 혁신적인 통합 아키텍처: 멀티모달 인코더가 필요 없습니다. 영상 및 오디오 입력이 LLM 백본으로 직접 전달됩니다.
- 고급 추론: 벤치마크 성능이 260억 달러 규모 모델에 근접하여 강력한 다단계 추론 및 에이전트 기반 워크플로우를 구현합니다.
- 노트북에 적합: 16GB의 VRAM 또는 통합 메모리만으로도 로컬에서 실행할 수 있을 만큼 작은 용량입니다.
- 개방적이고 접근성이 뛰어남: Apache 2.0 라이선스 하에 배포되며 개발자 생태계 전반에 걸쳐 지원됩니다.
- 드래프팅 준비 완료: Gemma 4 12B는 지연 시간을 줄이기 위해 멀티 토큰 예측(MTP) 드래프팅 기능을 갖추고 있습니다.
이러한 기능들을 종합하면 속도나 추론 능력을 희생하지 않고도 일상적인 하드웨어에 고급 멀티모달 기능을 제공할 수 있습니다. 이제 Gemma 4 12B가 어떻게 이를 구현하는지 자세히 살펴보겠습니다.
최첨단 에이전트를 로컬에서 실행하세요
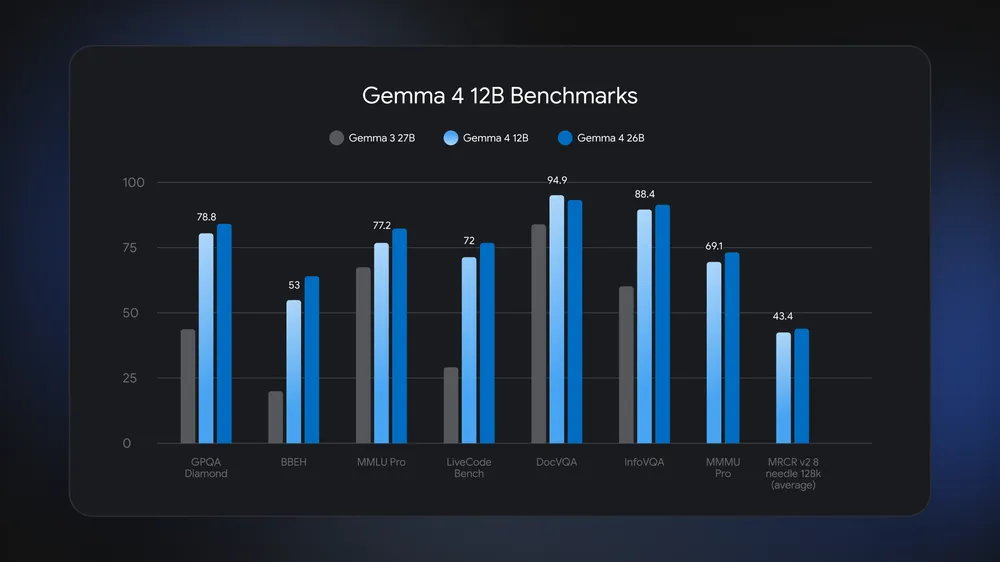
Gemma 4 12B는 표준 벤치마크에서 더 큰 26B MoE 모델에 버금가는 성능을 제공하지만, 전체 메모리 사용량은 절반 이하입니다. 16GB RAM을 탑재한 일반 노트북에서도 로컬로 실행할 수 있을 만큼 작아, 강력한 멀티모달 및 에이전트 기반 환경을 노트북에서 바로 구현할 수 있습니다.
독보적으로 효율적인 통합 아키텍처를 경험해 보세요.
Gemma 4 12B의 가장 큰 특징은 시각 및 오디오 입력을 처리하는 간소화된 접근 방식입니다. 기존의 멀티모달 모델은 일반적으로 이미지와 오디오를 변환하기 위해 별도의 인코더를 사용한 후, 변환된 표현을 언어 모델에 전달합니다. 이러한 분리된 인코더는 지연 시간을 증가시키고 메모리 사용량을 늘리기 때문에, Gemma 4 12B는 오디오와 시각 입력을 직접 통합하는 인코더 없는 아키텍처로 학습되었습니다.
Gemma 4 12B가 멀티모달 입력을 기본적으로 처리하는 방법은 다음과 같습니다.
- 비전: Gemma 4의 비전 인코더를 단일 행렬 곱셈, 위치 임베딩 및 정규화로 구성된 경량 임베딩 모듈로 교체했습니다. 이를 통해 LLM 백본이 시각 처리를 담당할 수 있게 되었습니다.
- 오디오: 오디오 처리를 더욱 간소화했습니다. 오디오 인코더를 완전히 제거하고 원시 오디오 신호를 텍스트 토큰과 동일한 차원 공간으로 투영했습니다.
자세한 내용을 알고 싶은 개발자분들은 저희의 Gemma 4 12B 개발자 가이드를 참조해 주세요 .
네이티브 오디오 처리 기능을 직접 확인해 보세요. Gemma 4 12B가 Google AI Edge Eloquent 앱을 사용하여 음성 입력을 완전히 오프라인에서 텍스트로 변환, 서식 지정 및 번역하는 과정을 살펴보세요.
오늘 바로 시작하세요
- 직접 시도해 보세요 : LM Studio , Ollama , Google AI Edge Gallery 앱 , Google AI Edge Eloquent 앱 및 LiteRT-LM CLI 에서 몇 번의 클릭만으로 실험해 볼 수 있습니다.
- 가중치 다운로드 : 사전 학습되고 명령어에 맞춰 조정된 체크포인트를 Hugging Face 와 Kaggle 에서 직접 다운로드하세요 .
- 통합 및 학습: 개발자 문서 와 빠른 시작 노트북을 검토하세요 .
- 선호하는 개발 도구를 사용하세요 . Hugging Face Transformers , llama.cpp , MLX , SGLang , vLLM을 사용하여 로컬 추론 파이프라인을 구현 하거나 Unsloth를 사용하여 효율적으로 미세 조정할 수 있습니다 .
- Gemma 스킬로 에이전트 개발의 가능성을 열어보세요: 최신 Gemma 기능을 활용하여 에이전트 개발을 지원하기 위해 공식 스킬 저장소를 출시합니다 . 이 저장소는 에이전트가 Gemma 모델을 사용하여 개발할 수 있도록 특별히 설계된 스킬 라이브러리입니다.
- 원하는 방식으로 배포하세요: Google Cloud를 사용하여 프로덕션 환경에 엔드포인트를 배포합니다. Gemini Enterprise Agent Platform Model Garden , Cloud Run 및 GKE를 통해 원하는 방식으로 배포할 수 있습니다 .
설치만 해서 돌리면 실망하시겠지만 기본 하네스 구성만 하면 가족들이 가볍게 써볼만한 수준은 될 겁니다.
일반RAM 기반으로는 많이 답답하실 것이므로 16GB 노트북 이용자께서는 더 작은 모델로 시도하시는 것이 좋을 것 같습니다.